How Transformers Actually Work: Encoders, Decoders & Attention Explained
If you have used ChatGPT to draft an email, asked Claude to debug Python code, or used Gemini to summarize a 50-page PDF, you have interacted with a Transformer.
Before 2017, artificial intelligence struggled to write coherent paragraphs, let alone reason through complex logic or generate entire software applications. Then a team of Google researchers published a paper called "Attention Is All You Need." That paper introduced the Transformer architecture and quietly triggered the most significant technological shift since the internet.
But how do transformers actually work? Open the original research paper and you are greeted by dense linear algebra and intimidating diagrams. This guide goes completely visual. We strip away the math and build your intuition step by step. By the end, you will understand how transformers process language, what attention really means, and how models like ChatGPT generate their responses.
- Why transformers replaced RNNs and LSTMs so completely
- How tokens, embeddings, and attention work together
- The difference between encoders and decoders
- How positional encoding solves the order problem
- Why ChatGPT is decoder-only, and how it generates text word by word
- Why AI hallucinations happen, and what can be done about them
- Why Transformers Changed AI
- The Problem With Older Models (RNNs)
- What Is a Transformer?
- Tokens and Embeddings
- The Core Idea of Attention
- Self-Attention Explained Visually
- Multi-Head Attention
- Encoders Explained
- Decoders Explained
- Positional Encoding
- How ChatGPT Generates Text
- Why LLMs Hallucinate
- Why Transformers Scale So Well
- Common Beginner Misconceptions
- Real-World Transformer Walkthrough
- Conclusion
- FAQ
1. Why Transformers Changed AI
To understand why transformers are revolutionary, you need to start with one word: context.
Human language is inherently messy. Words change meaning depending on the words around them. A "bank" can be a financial institution or the edge of a river. Sarcasm, idioms, and multi-paragraph arguments all require a persistent, deep understanding of what came before. Before transformers, AI models processed language like someone tracing their finger across a page, reading one word at a time and constantly losing track of earlier context.
Transformers introduced a way for AI to look at an entire sentence, or an entire chapter, all at once.
Attention allows transformers to dynamically redefine the meaning of a word based on surrounding context. By processing data in parallel rather than sequentially, transformers can capture massive amounts of information simultaneously, something that was simply impossible for earlier architectures.
2. The Problem With Older Models (RNNs)
Before 2017, the gold standard for Natural Language Processing was the Recurrent Neural Network, or RNN. RNNs processed text sequentially. Given the sentence "The cat sat on the mat," an RNN would read "The", update its internal memory, then read "cat", update again, and so on.
This created two critical bottlenecks:
The hardware bottleneck. Because RNNs read word by word, they could not take advantage of modern GPUs, which are designed to run thousands of calculations at the same time. Training was painfully slow.
The telephone game problem. Have you ever played the telephone game, where a message whispered down a line is completely distorted by the end? By the time an RNN reached the end of a long paragraph, it had effectively "forgotten" the first sentence. The further away information was, the weaker its influence became.
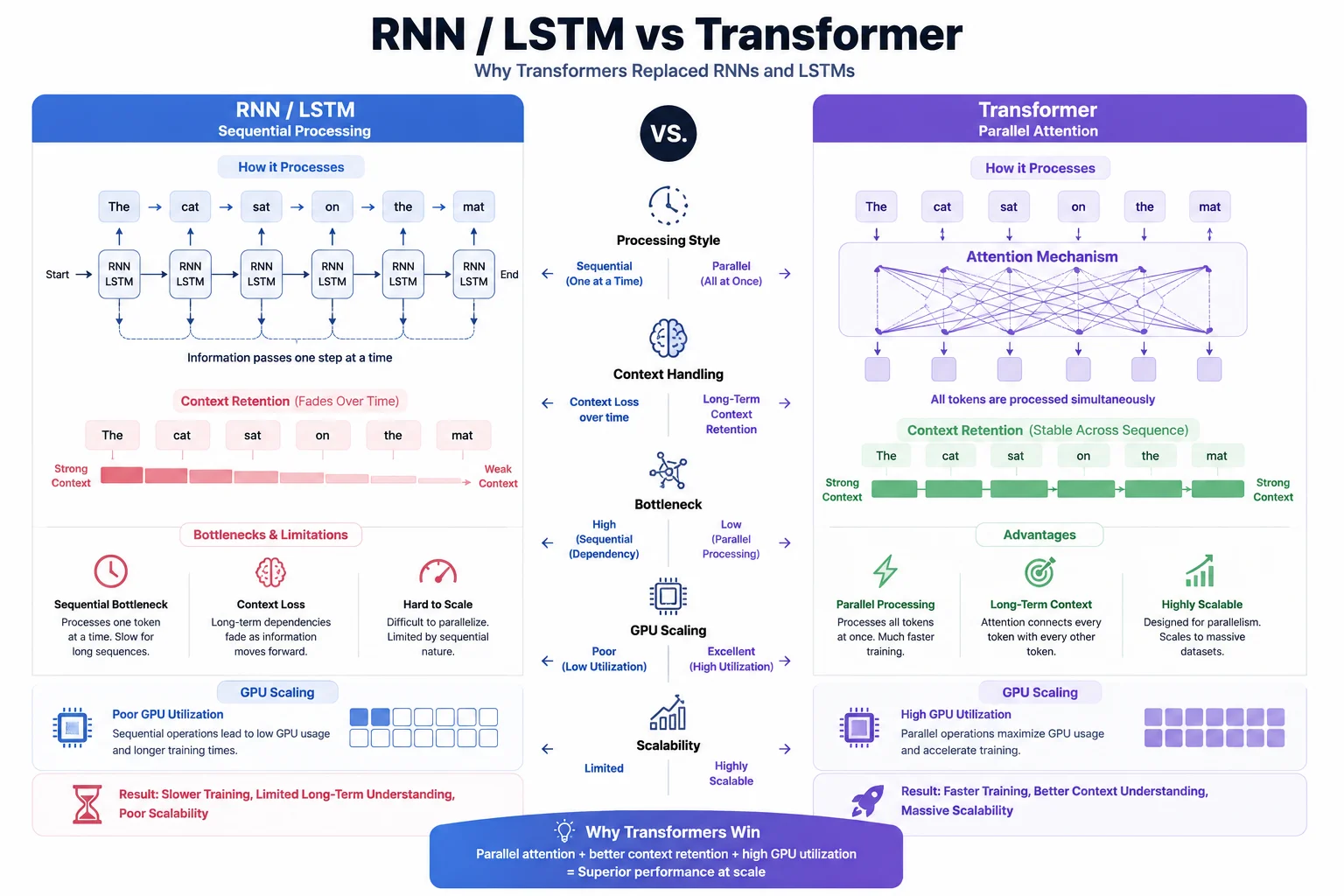
Many beginners think transformers are just "bigger, faster" RNNs. They are not. Transformers abandoned the concept of sequential reading entirely. It is a fundamentally different architecture built on a completely different idea.
Older AI read text like a ticker tape, one word at a time. This was too slow to train on massive datasets and caused the model to lose context in long conversations. Transformers solved both problems at once.
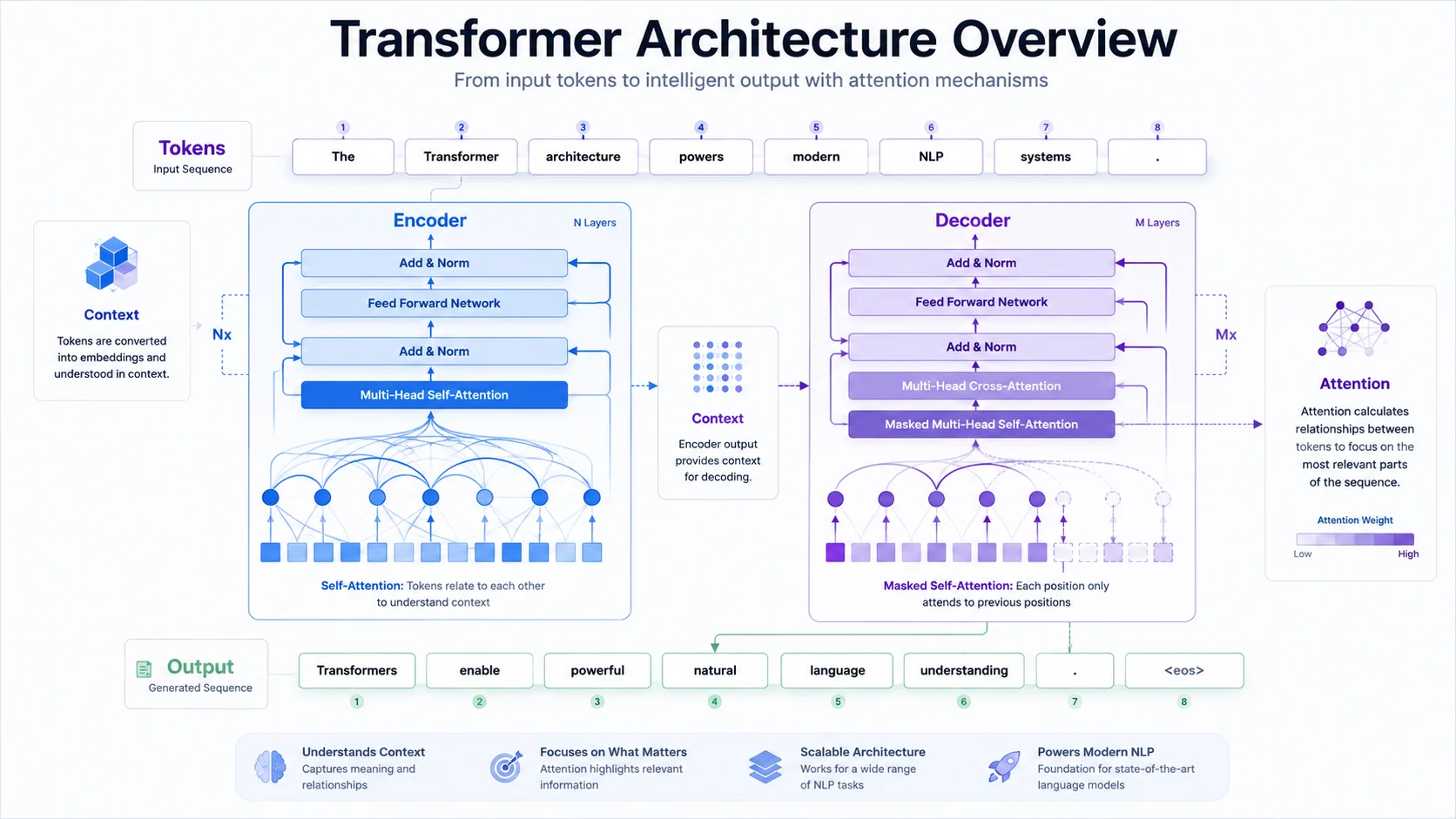
3. What Is a Transformer?
At its core, a transformer is a neural network architecture designed to process sequential data by tracking relationships between all elements simultaneously.
Think of it as a highly organized assembly line with two main factories:
- The Encoder reads the input text and builds a deeply contextualized mathematical understanding of it.
- The Decoder takes that understanding and generates a new sequence, one token at a time.
But before we can walk into these factories, we need to understand the raw materials they use. AI does not read letters or words. It reads numbers. We bridge that gap using tokens and embeddings.
4. Tokens and Embeddings
To feed text into a transformer, we first need to translate human language into geometry.
Step 1: Tokenization
We chop the text into pieces called tokens. A token can be a whole word, a syllable, or even a single character, depending on the tokenizer used.
Input: "ChatGPT is amazing!"
Tokens: ["Chat", "G", "PT", " is", " amazing", "!"]
Step 2: Embeddings
Next, we assign each token a large list of numbers called a vector that represents its core meaning. This is called an embedding.
Picture a massive map floating in space where you plot words based on their definitions. "Apple" sits close to "Banana" but far from "Carburetor." In modern LLMs, this map has thousands of dimensions. Because words are now coordinates in space, the AI can do actual math with language. The classic example:
King - Man + Woman = Queen
Imagine an embedding map for animals. If you have the coordinates for "Puppy" and "Dog," what word would you land on if you applied that same mathematical distance starting from "Cat"?
Answer: Kitten. The relationship between a young animal and its adult form is a consistent geometric direction in embedding space.
Embeddings are excellent at grouping similar concepts, but they are static. The dictionary definition of "lead" does not tell you if we are talking about a heavy metal or the front of a race. To resolve that ambiguity, we need Attention.
5. The Core Idea of Attention
This is where transformers change the game. The transformer uses an Attention Mechanism to dynamically update the meaning of a word based on its neighbors.
Read this sentence:
"The animal didn't cross the street because it was too tired."
As a human, you instantly know "it" refers to the animal. Older AI models struggled with exactly this kind of ambiguity. When a transformer reads this sentence, the attention mechanism draws mathematical connections between "it" and every other word. It scores them for relevance, realizes "animal" is the best match for "tired," and blends the meaning of "animal" into the representation of "it."
Now read: "The trophy didn't fit into the suitcase because it was too large."
Answer: The trophy. Attention shifted the meaning of "it" based entirely on the adjective "large" vs "tired." The same mechanism, applied to a different context, produces a completely different result.
6. Self-Attention
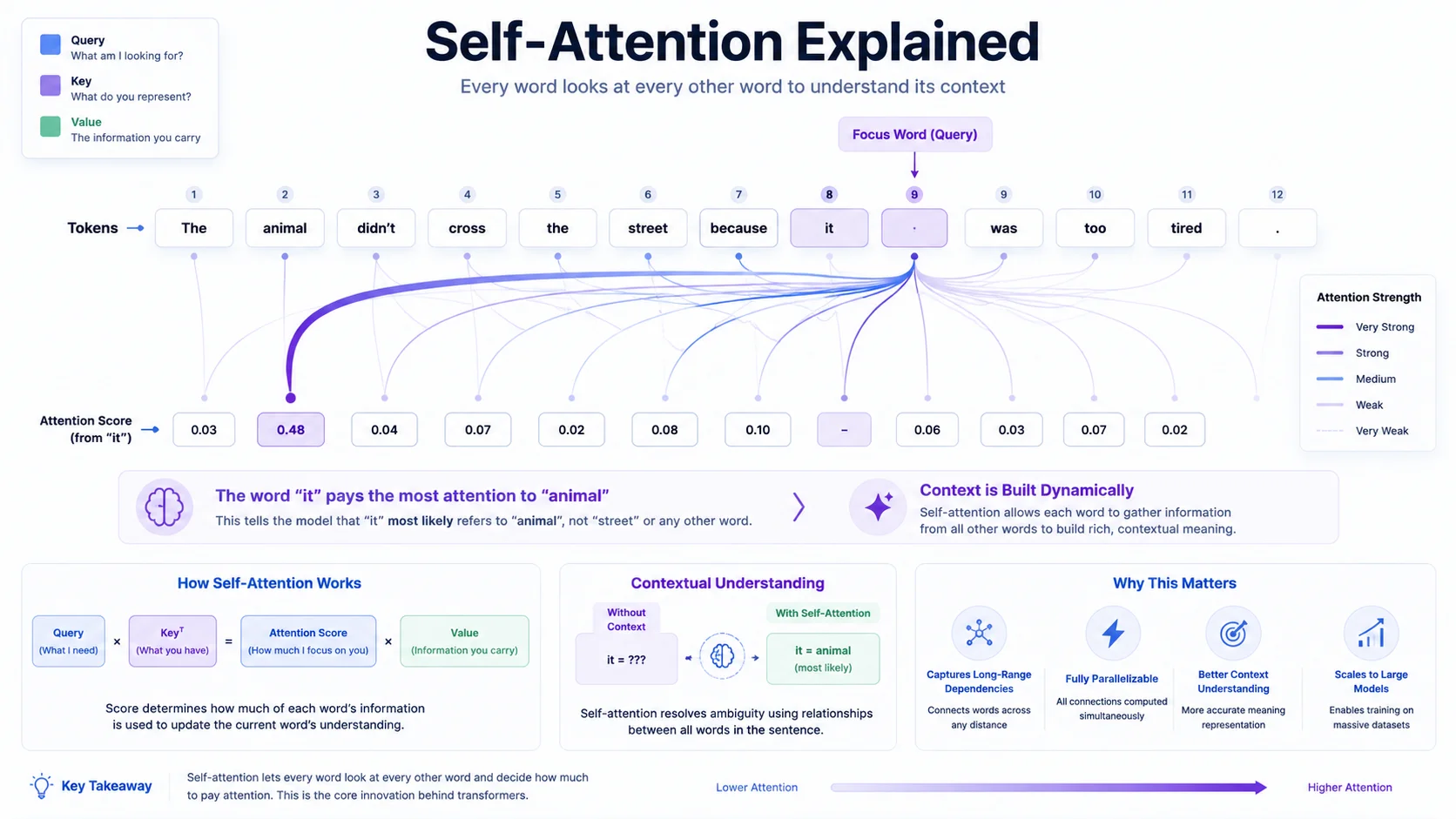
Let's look at how attention is actually calculated. The transformer uses three concepts: Queries (Q), Keys (K), and Values (V).
Picture yourself walking into a massive library:
- Query (Q): What you are looking for. "I need a book about AI."
- Key (K): The title on the spine of every book. "Introduction to Transformers."
- Value (V): The actual text inside the book.
In a transformer, every single token acts as a Query, a Key, and a Value simultaneously. Here is what happens with the word "it" from our earlier example:
- "it" broadcasts a Query: "I am a pronoun. I need a noun that can be tired."
- "animal" broadcasts a Key: "I am a noun. I am a living thing capable of fatigue."
- The transformer multiplies the Query and Key together. They are a strong match, producing a high Attention Score.
- The transformer takes the Value of "animal" and weaves it into the embedding for "it."
People think attention works like human "focus." In reality, it is a precise matrix of mathematical weights, a scoring system calculating how strongly one vector should alter the meaning of another. The mechanism is pure algebra, yet the results feel remarkably intuitive.
7. Multi-Head Attention
Language is multi-layered. When you read a sentence, you are simultaneously processing grammar, emotional tone, named entities, and logical flow. A transformer replicates this by calculating attention multiple times in parallel using Multi-Head Attention.
Instead of running attention once, it runs it many times simultaneously, often 96 times in parallel for large models like GPT-4. Think of it as a panel of literary critics analyzing a poem at the same moment:
- Head 1 tracks grammar, connecting verbs to their subjects.
- Head 2 tracks emotional sentiment, linking positive or negative words.
- Head 3 tracks named entities, connecting people to their actions.
If you prompt an AI with "The stock market crashed, leaving investors devastated," which attention head (Grammar, Emotion, or Entities) would most strongly link "devastated" to "crashed"?
Answer: Emotion. The semantic relationship between the two words is about sentiment, not grammar or named entities.
- Embeddings turn words into geometry in high-dimensional space.
- Attention dynamically links context across any distance in a sequence.
- Multi-Head Attention evaluates multiple dimensions of meaning simultaneously.
8. Encoders Explained
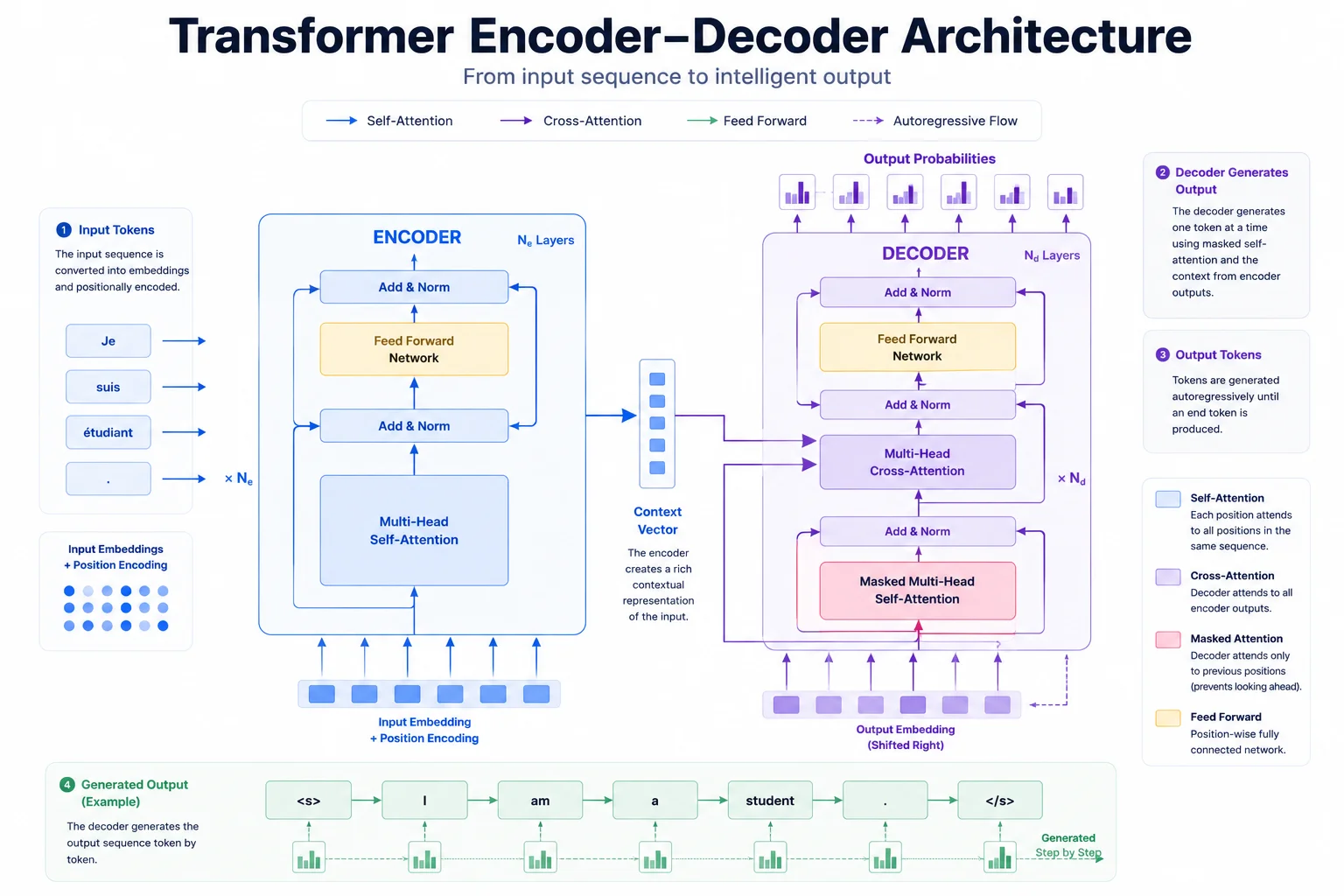
Now that we understand attention, let's look at the first major architectural block: the Encoder.
The Encoder's job is to take raw input tokens and compress them into a deeply contextualized "thought." Here is what happens step by step:
- Tokens enter and are converted into embeddings.
- They pass through a Self-Attention layer, where every token communicates with every other token to gather context.
- They pass through a Feed-Forward Neural Network, which solidifies each token's updated meaning.
- This entire process repeats through a stack of Encoder blocks, sometimes up to 96 layers deep in the largest models.
The final output is a Context Vector: a rich mathematical matrix where every single token perfectly understands its role within the full input.
The encoder does not produce text. It produces understanding. The Context Vector is not a summary; it is a mathematical representation of the full meaning of the input, including every contextual relationship between every token.
9. Decoders Explained
If the Encoder is the reader, the Decoder is the writer. Its job is to generate new text using the understanding the Encoder built.
The Decoder is structurally similar to the Encoder but with two crucial differences:
Masked Self-Attention. When generating text, the model is not allowed to "cheat" by looking at future words it has not produced yet. A mask hides all future tokens so the model must predict each word based only on what it has already written.
Encoder-Decoder Attention. The Decoder looks at the Context Vector provided by the Encoder and constantly asks: "Based on what I've written so far, and based on the full context I received, what should the next word be?"
Encoders compress inputs into deep context. Decoders use that context to generate outputs. This separation is what makes encoder-decoder systems so powerful for tasks like translation, summarization, and question answering.
10. Positional Encoding: The Missing Piece
Wait. If transformers process all tokens simultaneously, how do they know the order of words?
To a model reading everything in parallel, "The dog bit the man" and "The man bit the dog" look mathematically identical. The same tokens, just rearranged.
Imagine someone hands you a beautifully written chapter, but every word has been cut out and dropped into a bag. You have all the right words but no story.
To solve this, transformers use Positional Encoding. Before the embeddings enter the network, a unique mathematical "timestamp" is added to each token:
- Word 1: Embedding + Position 1
- Word 2: Embedding + Position 2
- And so on...
Modern models like Llama and Mistral use Rotary Positional Embeddings (RoPE), which encode position directly into the attention calculation rather than adding it to the embeddings. This gives much better performance at long context lengths.
Positional encoding guarantees that even though the transformer reads everything in parallel, it still mathematically knows the grammar and sequence of your prompt. Without it, "the cat sat on the mat" and "the mat sat on the cat" would be indistinguishable.
11. How ChatGPT Generates Text
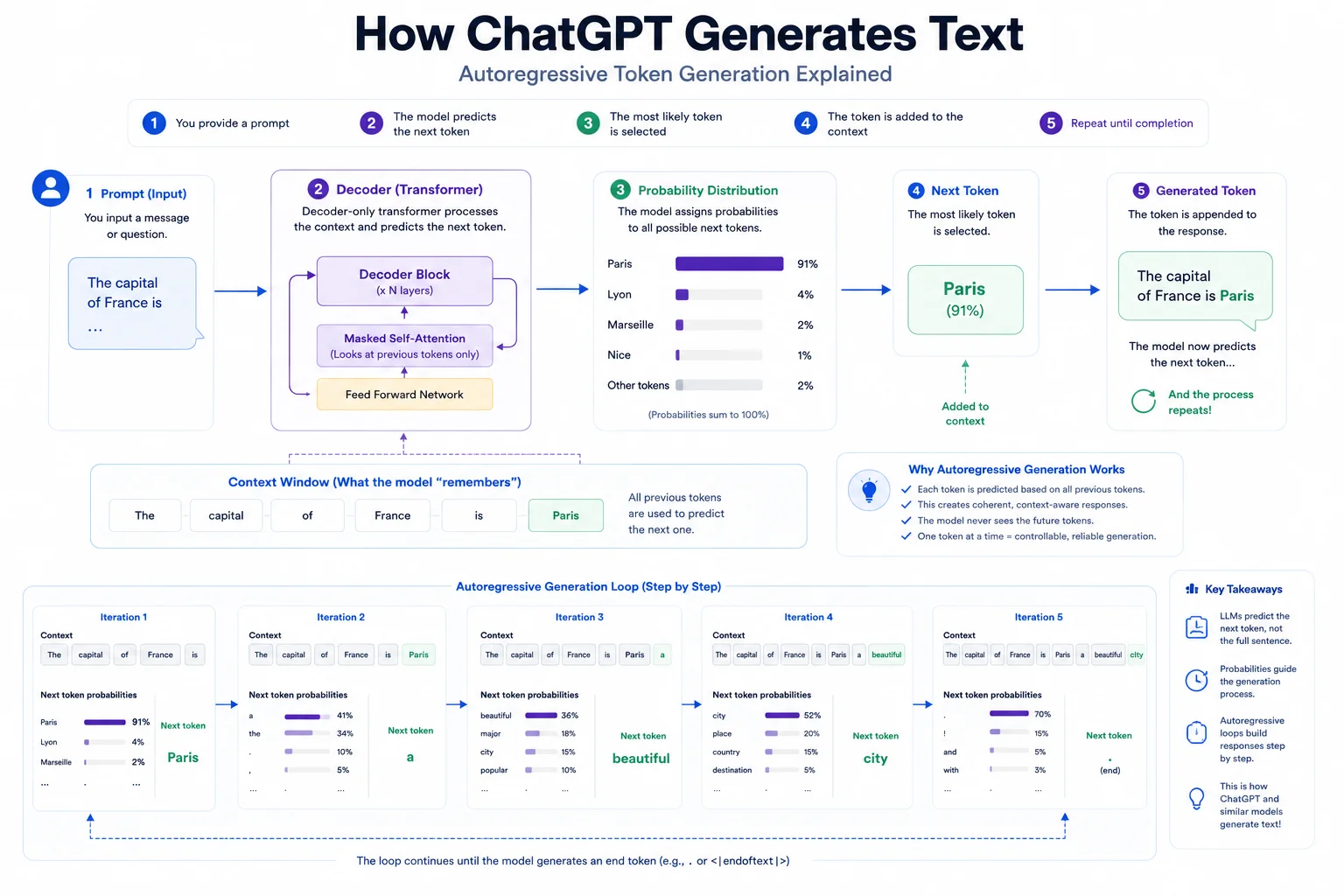
Here is a fascinating architectural secret: ChatGPT does not use an Encoder.
The original 2017 Transformer was designed for translation tasks: French enters the Encoder, English exits the Decoder. But OpenAI researchers realized that for conversational AI, you only need the Decoder. Models like GPT-4, Claude, and Gemini are primarily decoder-only architectures.
They generate text using a process called Autoregressive Generation:
- You type a prompt: "Tell me a joke."
- The Decoder processes the prompt and predicts the highest-probability next token: "Why"
- It appends that token and runs the entire calculation again: "Tell me a joke. Why" → "did"
- This loop continues at high speed until the model predicts an <EOS> (End of Sequence) token.
Imagine an LLM has generated: "The capital of France is P". What happens next?
Answer: The entire sequence is fed back into the model. The attention mechanism calculates that the highest probability next token, given everything that came before, is "aris." Not because the model "knows" geography, but because "Paris" is statistically overwhelmingly associated with "capital of France" in the training data.
12. Why LLMs Hallucinate
Understanding autoregressive generation directly explains why AI sometimes hallucinates, confidently presenting false information as fact.
Because LLMs do not reference a database of truth, they act as massive plausibility engines. They predict the most statistically likely next word based on patterns learned during training. If you ask an AI a tricky question, it does not know the answer is wrong. It simply calculates that a specific sequence of words looks like a highly probable, well-structured response.
Hallucinations happen because transformers optimize for probabilistic fluency, not factual accuracy. They are designed to sound plausible. This is why modern AI systems often pair transformers with RAG (Retrieval-Augmented Generation) to ground responses in verified, real-time data rather than relying solely on learned statistical patterns.
13. Why Transformers Scale So Well
Why did transformers cause the modern AI boom? One word: parallelism.
Because older RNNs processed text sequentially, adding more GPUs barely helped. Transformers process all tokens in parallel, which means AI researchers could suddenly leverage the massive parallel processing power of modern GPU clusters. If you want a smarter transformer, you simply add more layers, more attention heads, and more training data. The architecture scales predictably.
This scalability unlocked everything from modern coding copilots to multimodal AI. It also explains the Chinchilla scaling laws: given a compute budget, you get better results by balancing model size and training data size rather than just making the model larger.
14. Common Beginner Misconceptions
They do not possess consciousness or a physical understanding of reality. They calculate contextual probability relationships between tokens. The outputs can feel remarkably human, but the mechanism is purely mathematical.
LLMs do not store a hard drive of Wikipedia articles. They compress the patterns of human knowledge into neural weights, numbers that encode statistical relationships between concepts. This is why they can generate novel sentences rather than just copy-pasting existing text.
Model size matters, but training data quality, diversity, and the ratio of compute to parameters matter just as much. A well-trained smaller model often outperforms a poorly trained larger one on real-world tasks.
15. Real-World Transformer Walkthrough
Let's put everything together. Imagine a classic encoder-decoder transformer translating "Hello, world!" into French: "Bonjour le monde!"
| Step | What Happens | Component |
|---|---|---|
| 1 | The English sentence is split into tokens and converted into embeddings. Position stamps are added. | Tokenizer + Embeddings |
| 2 | Self-attention maps the relationship between "Hello" and "world." The encoder produces a Context Vector. | Encoder Stack |
| 3 | The decoder receives the Context Vector and a <START> token. It calculates probabilities and outputs "Bonjour." | Decoder Step 1 |
| 4 | The decoder takes "Bonjour" + the Context Vector, calculates again, and outputs "le." | Decoder Step 2 |
| 5 | It takes "Bonjour le" + Context Vector and outputs "monde." | Decoder Step 3 |
| 6 | The model predicts an <EOS> token and stops. | Generation Complete |
Every time you receive a response from ChatGPT, Claude, or Gemini, that exact loop ran thousands of times in a fraction of a second. Each token in the response was individually predicted. Each prediction considered the full context of everything that came before it. The next time an AI produces a surprisingly coherent paragraph, you now know exactly how it happened.
16. Conclusion
The transformer architecture broke the sequential bottleneck of earlier AI. By introducing self-attention, it gave neural networks the ability to view language holistically, understanding vast webs of context in parallel across millions of tokens.
Whether it is an AI agent analyzing financial documents, a copilot writing Python code, or ChatGPT answering a question, the underlying mechanism is the same: words become geometry, attention routes meaning across dimensions, and autoregressive generation produces one token at a time until the thought is complete.
The next time you use an AI tool, picture millions of Queries, Keys, and Values actively routing attention across thousands of dimensions to produce that single, coherent response. It is not magic. It is very clever mathematics applied at enormous scale.
Frequently Asked Questions
A transformer is a deep learning architecture introduced by Google in 2017. It processes sequential data in parallel rather than sequentially. Combined with a self-attention mechanism, this parallelization lets it understand complex context and scale massively, forming the foundation of every modern Large Language Model.
Self-attention is a mathematical mechanism that evaluates how important every word in a sequence is to every other word. It dynamically updates a word's meaning based on surrounding context, solving pronoun ambiguity and long-range dependencies that older RNN models consistently failed at.
RNNs read text sequentially, making them slow to train and prone to forgetting earlier context. Transformers process all tokens simultaneously in parallel. This removes memory bottlenecks, lets modern GPU clusters train far larger models, and enables much stronger long-range understanding across an entire document.
ChatGPT uses a decoder-only transformer. It takes your prompt, predicts the most statistically likely next token, appends it to the prompt, then repeats this loop at high speed. The result is fluent text generated one piece at a time until the model predicts an end-of-sequence token.
Because transformers process all tokens simultaneously, they would lose track of word order without extra help. Positional encoding adds a unique mathematical position value to each token's embedding before it enters the network. This lets the model distinguish "dog bit man" from "man bit dog."
The encoder reads input and builds a contextualised mathematical understanding, essentially a thought about the prompt. The decoder uses that understanding to generate output one token at a time. BERT uses encoder-only for understanding tasks. GPT-style models use decoder-only for text generation.
Hallucinations happen because transformers are probability engines, not fact databases. They predict the most statistically likely next word based on learned patterns, not by checking a source of truth. Systems like RAG (Retrieval-Augmented Generation) address this by grounding responses in real, verified data.
Long Short-Term Memory (LSTM) is a type of Recurrent Neural Network with gating mechanisms that selectively remember or forget information over time. LSTMs were the gold standard for NLP before 2017. Transformers replaced them by processing all tokens in parallel, handling much longer contexts, and scaling far more efficiently on modern GPU hardware.
Multi-head attention runs the attention mechanism multiple times in parallel, each head learning to focus on a different type of relationship such as grammar, sentiment, or named entities. The outputs are combined and projected back into the model's representation space, letting the transformer capture multiple dimensions of meaning simultaneously.
BERT uses an encoder-only transformer trained with masked language modeling. It reads the full sentence bidirectionally, making it excellent for understanding and classification tasks. GPT uses a decoder-only architecture trained autoregressively, predicting the next token, which makes it suited for text generation. BERT understands; GPT generates.