You Are the Harness
Why the future belongs to people who can orchestrate AI tools effectively
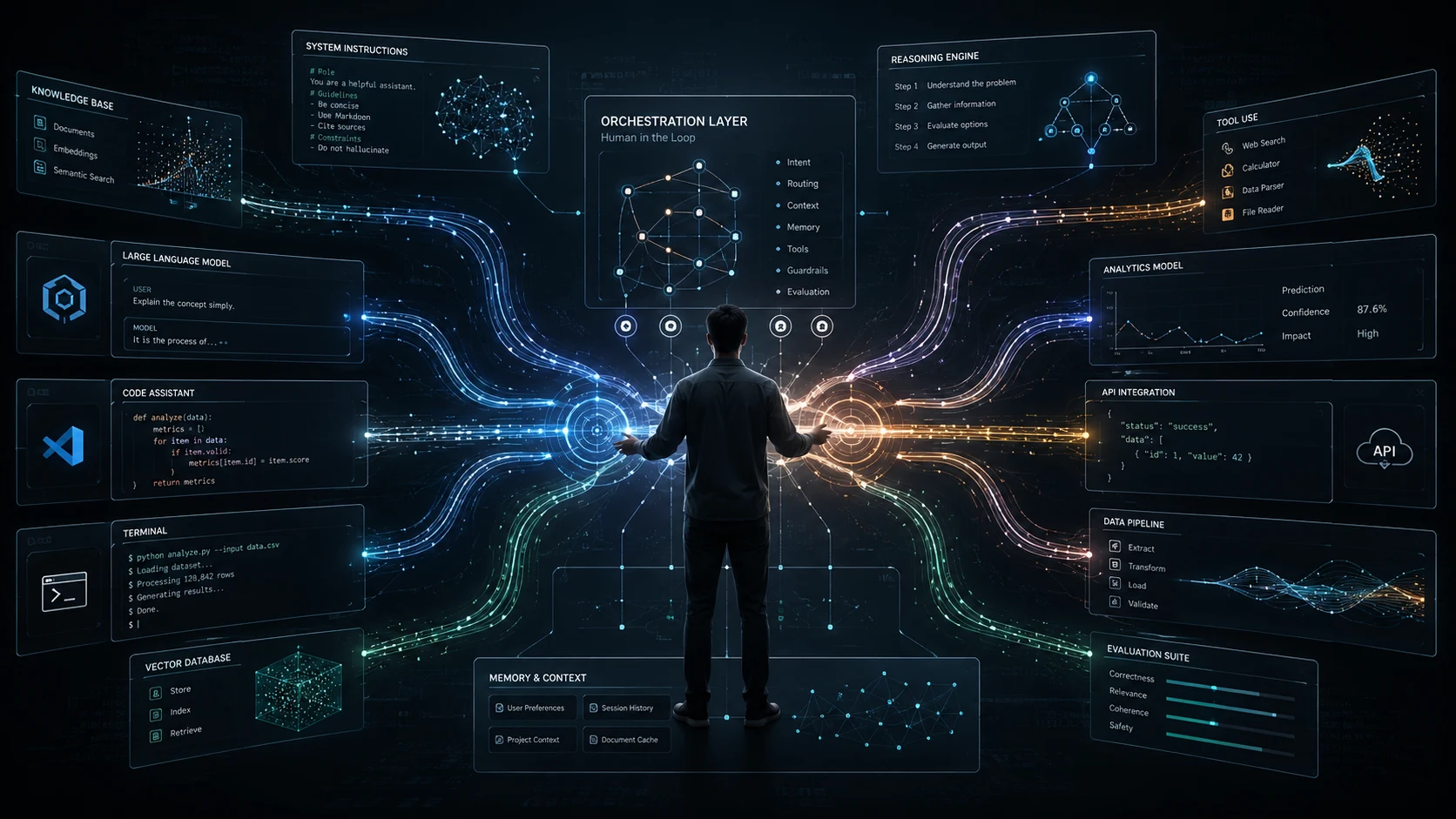
Most people still view artificial intelligence through the lens of a single, magical oracle. They imagine a singular text box where you type a request, wait a few seconds, and receive a perfectly packaged answer. This is the prevailing public narrative: that AI is a monolithic brain, and your only job is to ask it the right questions.
But if you look at how a senior engineer, a technical founder, or an AI-native worker actually operates today, the process looks entirely different. They are rarely sitting in a single chat interface. Instead, they bounce between browser tabs, IDEs, and terminal windows. They feed the output of one model into the input of another. They test Claude against ChatGPT, use Perplexity to verify claims, and run local LLMs to process sensitive corporate data.
The cognitive stack is multiplying faster than any individual can fully evaluate. New models drop weekly, context windows expand by orders of magnitude, and benchmarks are constantly shattered. The concept of a single, omnipotent AI is already obsolete. The models themselves are rapidly becoming infrastructure. The real advantage lies not in the specific tool you use, but in the distributed system you build to manage them.
- The Shift From Single AI to Distributed Intelligence
- Raw Power Isn't Enough
- What Different Models Are Actually Good At
- The Missing Link: The Context Burden
- How Skilled Users Actually Sequence Work
- Where Multi-Model Routing Still Fails
- Why Prompting Is Not Enough Anymore
- Local Models Are Quietly Catching Up
- The Real Bottleneck Is Becoming Human Coordination
- FAQ
The Shift From Single AI to Distributed Intelligence
In late 2022, ChatGPT felt like a singular destination. It was the monolithic interface for assistance, where you went to write code, draft emails, and brainstorm ideas because it was the only viable game in town.
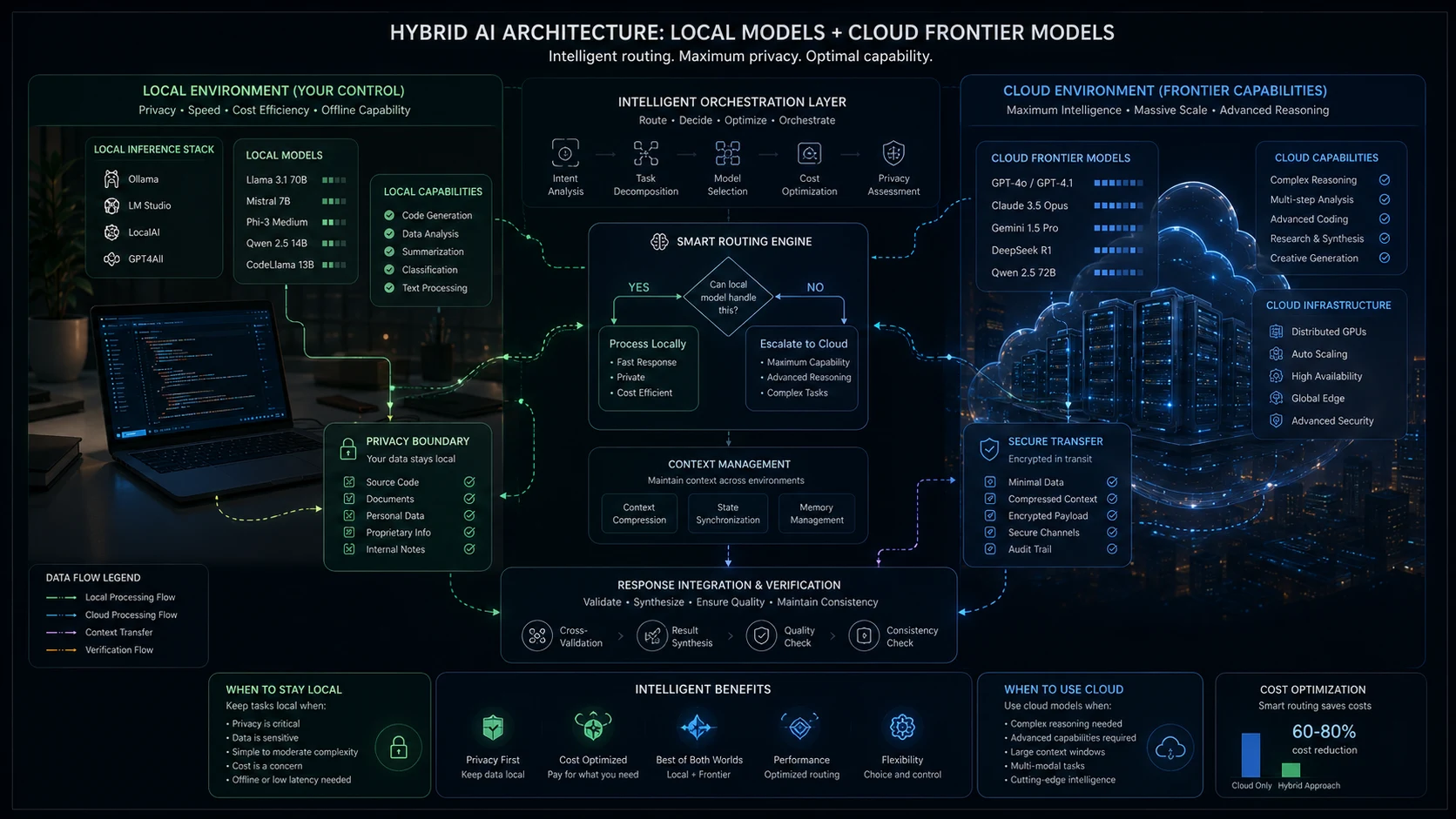
Today, relying on a single model is like trying to build a house using only a hammer. The AI landscape has fractured into highly specific domains, and treating all tools as interchangeable is a fast track to mediocre results.
We have entered an era of multi-model coordination. The most effective professionals have adapted by treating these tools not as independent assistants, but as execution nodes in a broader pipeline. Instead of asking one model to research, outline, write, and edit a complex technical document, the task is decomposed. Information is routed. State is manually carried over from one interface to another. Outputs from one system are aggressively validated by another.
This shift perfectly mirrors the evolution of software architecture. Just as the industry moved from hosting monolithic applications on bare metal to managing specialized microservices via Kubernetes, AI usage is transitioning from single-prompt chat windows to directed, multi-agent intelligence.
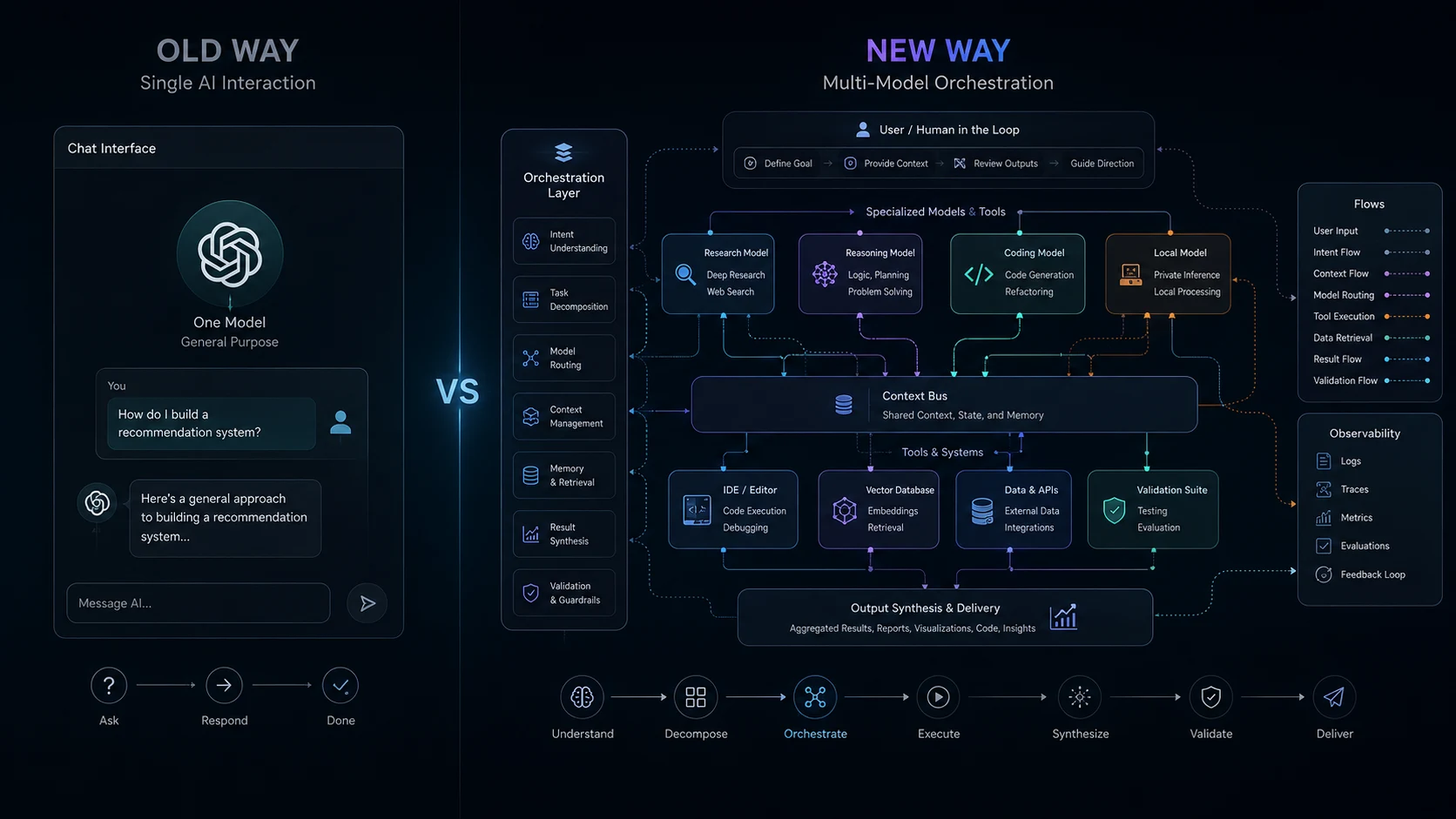
The leverage has shifted. Getting value out of AI is no longer about discovering a secret, perfect prompt. The execution flow matters more than the model. The real skill is knowing how to move data through a sequence of specialized layers to achieve a reliable result.
Raw Power Isn't Enough
To understand your evolving role in this ecosystem, consider the concept of horsepower.
A horse is a powerful engine, raw biological energy. But a team of horses, uncoordinated and pulling in different directions, does not move a carriage forward. It creates friction, chaos, and eventually, disaster. The power is abundant, but without alignment, it is useless.
The intelligence of large language models is the horsepower. It is raw, abundant, baseline compute. Every month, the cognitive horsepower available to the average person increases, while the cost to access it approaches zero. But horsepower requires a mechanism to capture, direct, and align it. That mechanism is the harness.

Your job is no longer to generate the raw intelligence or do the heavy lifting of drafting boilerplate code. Your job is to connect multiple systems, maintain the structural integrity of the flow, and ensure the resulting output aligns with reality.
What Different Models Are Actually Good At
To direct this horsepower effectively, you must deeply understand the material properties of the tools at your disposal. Choosing the right node requires balancing tradeoffs in reasoning depth, context limits, latency, privacy, and integration.
| Task Type | Best Tool Category |
|---|---|
| Real-time research & fact-checking | Perplexity |
| Deep reasoning & architecture | Claude |
| Broad coding, data analysis & multimodal | ChatGPT |
| Repo-aware software development | Cursor / GitHub Copilot |
| Massive context ingestion | Gemini |
| Sensitive data & private processing | Local LLMs (Llama, DeepSeek) |
Based on our practical experience. Model capabilities evolve rapidly, and your results may vary depending on the task, version, and use case.
ChatGPT (OpenAI)
Think of ChatGPT as the ultimate generalist. It remains exceptionally good at broad reasoning, quick iterative problem-solving, and handling multimodal inputs. Because it integrates natively with Python sandboxes, it is unmatched for data analysis, charting, and running scripts on the fly.
Claude (Anthropic)
Claude has become the industry standard for complex software architecture and natural writing. It is highly attentive to detailed system instructions and maintains deep coherence over large context windows. When you need to dump fifty pages of API documentation into a prompt and ask for a deeply analytical synthesis, Claude is the superior choice.
Gemini (Google)
Gemini is unmatched for ecosystem integration and sheer memory size. With context windows stretching into millions of tokens, it is less about traditional prompt-and-response and more about ingesting entire repositories, lengthy video files, or massive datasets that simply will not fit elsewhere.
Perplexity
Perplexity is the undisputed engine for research and citations. It bypasses the knowledge-cutoff problem by combining reasoning with real-time web scraping and retrieval-augmented generation (RAG). It is the tool for factual discovery and verifying technical claims before they enter your pipeline.
Cursor and GitHub Copilot
These represent embedded intelligence. They are not chatbots. They are context-aware coding environments. Cursor fundamentally changes software development by understanding your entire local codebase. It writes diffs across multiple files simultaneously, transforming the IDE into an active participant in the engineering process.
The Missing Link: The Context Burden
Connecting these disparate tools requires more than just copying and pasting text. As you move from one model to the next, you encounter the friction of memory loss. AI systems do not truly share memory. The API calls are stateless. The interfaces are isolated.
Because of this, the human operator must bear the context burden.
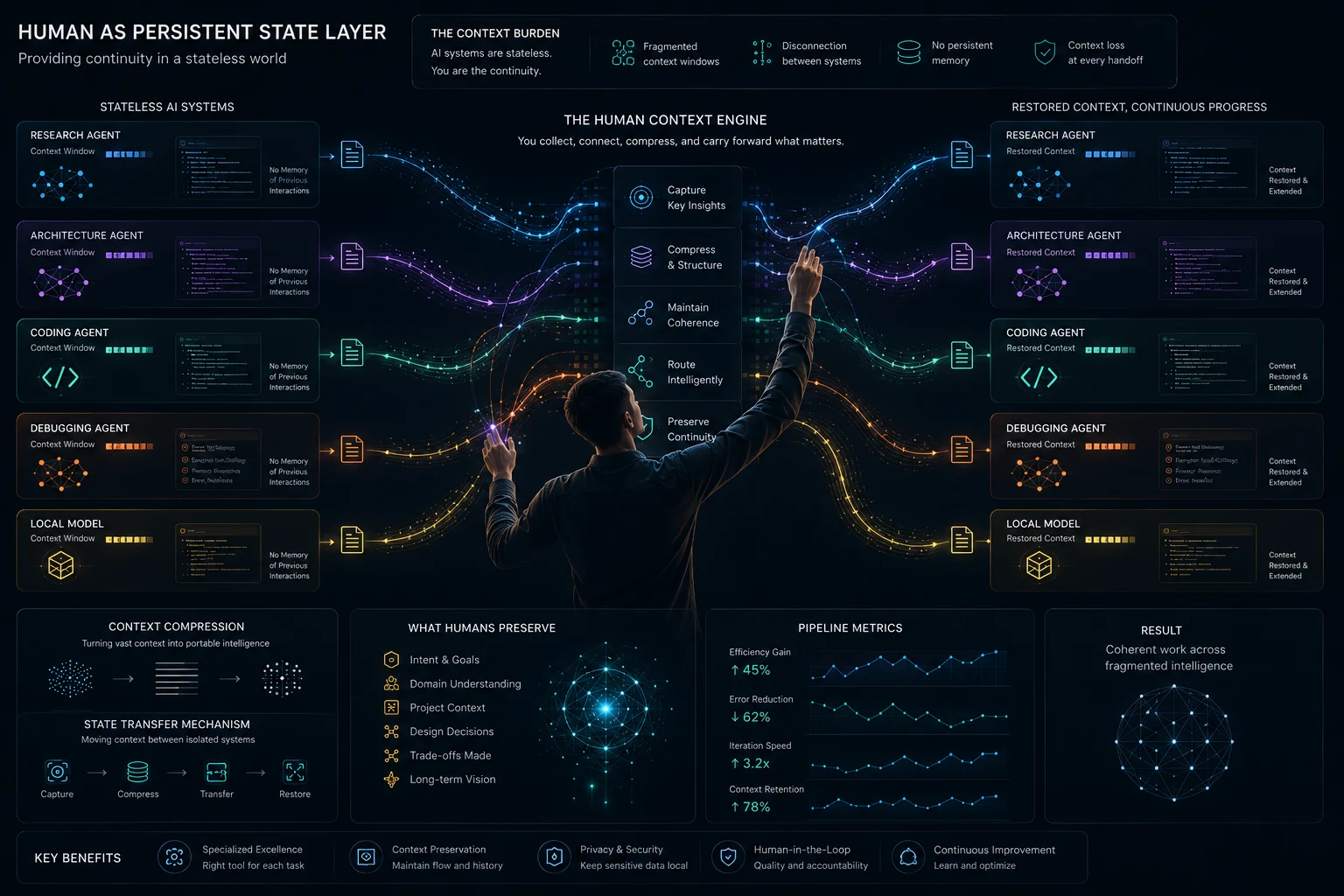
You are the persistent state layer. When you transition from Perplexity to Claude, you cannot bring the entire internet with you; you must compress the findings. When you move from Claude to Cursor, you must transfer the architectural intent without overwhelming the IDE with redundant conversational history.
How Skilled Users Actually Sequence Work
Skilled users do not expect one model to carry a complex project from zero to completion. They break the work down, route it, and validate the output. Consider a modern sequence for an engineer architecting a new software feature:
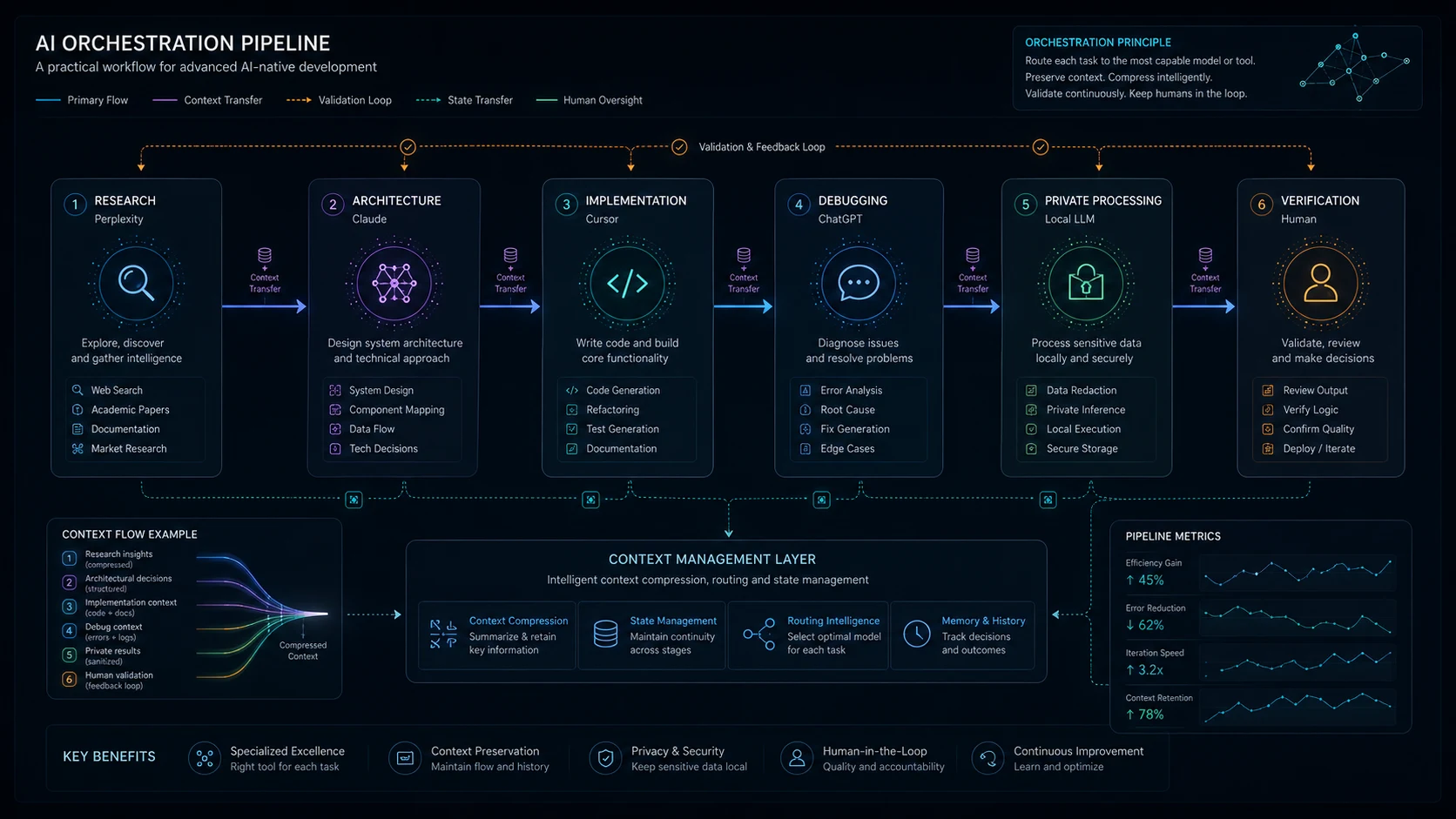
Phase 1: Discovery
The developer starts by querying Perplexity for the latest documentation on a specific third-party API to understand recent breaking changes. Perplexity provides the factual ground truth, complete with current links.
Phase 2: Logic and Architecture
The developer compresses the constraints gathered from Perplexity and pastes them into Claude. Leveraging Claude's superior ability to reason through complex logic, the developer asks it to design a system architecture, handle edge cases, and define the data models.
Phase 3: Implementation
Armed with a solid architecture document, the developer moves to Cursor. Using Claude's output as the foundational state, they begin coding. Cursor auto-completes boilerplate, suggests directory structures, and writes the implementation while holding the local codebase in memory.
Phase 4: Validation
If an obscure error trace appears, the developer bounces the isolated problem to ChatGPT for advanced data analysis. If the data involves raw, un-anonymized customer logs, they route it to a local LLM running on their machine to ensure total privacy.
Where Multi-Model Routing Still Fails
While this system is powerful, treating AI sequencing as a flawless panacea is a mistake. As pipelines become more complex, new failure modes emerge.
There is also the risk of context fragmentation. Bouncing between five different tools inevitably leads to information loss. The human layer can suffer from tool-switching fatigue, eventually losing track of the original intent or failing to notice when a model starts drifting off course.
Finally, there is the trap of excessive automation. Overcomplicated setups, where agents are endlessly prompting other agents without human supervision, often result in circular logic, bloated code, and spiraling API costs.
Because these pipelines are fragile, the solution is not just a better prompt. It is better systems thinking.
Why Prompting Is Not Enough Anymore
For the last two years, the tech industry fetishized "prompt engineering." People memorized magic phrases, hoping that starting a prompt with "Take a deep breath" would unlock hidden capabilities. But prompt engineering as a standalone discipline is standardizing. Models are getting smarter at interpreting sloppy instructions, and they increasingly optimize their own prompts under the hood.
A well-structured prompt can certainly improve a single output. But a well-designed execution flow compounds output quality dramatically.
Instead of spending three hours crafting the perfect zero-shot prompt in a single chat window, a systems thinker builds a multi-step workflow. They understand that AI performs best when it is constrained, guided, and given intermediate milestones.
When you stop viewing AI interactions as single-shot transactional queries and start viewing them as distributed systems, your capabilities scale. You stop trying to trick the model into being perfect, and instead design a flow that tolerates its imperfections.
Local Models Are Quietly Catching Up
While mainstream media focuses on the API battles between OpenAI, Google, and Anthropic, the local AI ecosystem is fundamentally altering how these pipelines are built. Models like Meta's Llama, Alibaba's Qwen, and DeepSeek are quietly matching the capabilities of proprietary models from just a year ago. Through techniques like quantization, it is now entirely feasible to run highly capable local inference directly on a standard MacBook.
Total Privacy and Security
If you are working with protected health information, proprietary corporate IP, or classified codebases, sending data to a cloud API is a non-starter. Local LLMs allow for powerful processing on-device. The data never leaves your silicon.
Zero Marginal Cost
API calls add up. If your task requires parsing ten thousand documents for basic entity extraction, cloud APIs can be prohibitively expensive. Running that same batch process on a local instance is practically free, costing only the electricity required to run your machine.
The Real Bottleneck Is Becoming Human Coordination
As models become faster, cheaper, and more intelligent, the primary constraint in the system is no longer the machine. The compute bottleneck is disappearing. The human bottleneck remains.
AI can generate infinite options. It can write a hundred variations of a Python function in seconds. It can draft entire project proposals in the time it takes to press return. But generating options is not the same as making progress. Progress requires judgment.
Humans must provide the intent. An AI can optimize a database query, but the human must decide if a relational database is the right architecture for the business problem. An AI can write a technically flawless essay, but the human provides the taste to know if it resonates with the target audience.
When you act as the harness, you hold the master plan. You know what step you are on, what data needs to move where, and what the final product is supposed to look like. Your value transitions from execution to synthesis. You are no longer paid for the raw mechanical output of typing code or writing words. You are paid for your ability to maintain the direction of the project, connect the systems, and take ultimate responsibility for the output deployed to production.
The AI will supply the cognitive velocity. You must supply the steering.
Conclusion

We are rapidly approaching a world where broad intelligence is ubiquitous, cheap, and easily accessible to everyone. When every developer, writer, and founder has access to the exact same baseline compute, the models themselves cease to be a competitive advantage. You cannot win simply by having access to ChatGPT.
The leverage shifts entirely to coordination. The future belongs to the individuals and organizations who can architect pipelines, combine disparate tools, and align immense computational power toward coherent, practical goals.
AI is the horsepower.
You are the harness.
Frequently Asked Questions
Being the harness means acting as the coordinator of multiple AI systems rather than a passive user of a single tool. Just as a harness aligns the power of multiple horses toward one direction, you connect different AI models, transfer context between them, validate their outputs, and maintain the overall intent of the project. The intelligence comes from the models; the direction comes from you.
The choice depends on the nature of the task. Perplexity excels at real-time research and fact-checking. Claude is strongest for deep reasoning, complex architecture, and large-document synthesis. ChatGPT handles broad coding, data analysis, and multimodal tasks well. Gemini is best for massive context windows and ecosystem integration. Cursor and GitHub Copilot are purpose-built for repository-aware software development. Local LLMs like Llama or DeepSeek are ideal when data privacy is non-negotiable or API costs are prohibitive.
The context burden is the cognitive and logistical work required to transfer relevant information between different AI tools. Because AI systems do not share memory, the human operator must manually summarize findings from one model, strip out noise, and construct an effective input for the next. Failing to manage this state properly causes intent drift, where the pipeline gradually loses alignment with the original goal.
For roughly 80% of routine tasks like summarization, data extraction, basic formatting, and entity recognition, modern quantized local models running on consumer hardware are entirely sufficient. Sophisticated practitioners build hybrid stacks that use local models for bulk processing and privacy-sensitive data, reserving cloud models for the final, most demanding reasoning steps.
Prompt engineering as a standalone discipline is standardizing. Models are becoming better at interpreting imprecise instructions. However, understanding how to structure prompts remains valuable as one component of a larger skill: pipeline design. The real leverage today comes from knowing how to decompose complex tasks, sequence them across the right tools, establish human-in-the-loop validation steps, and compress state effectively between models.