AI Security
The Architecture of Trust: How AI Watermarking and SynthID Work
Deepfakes are no longer a future threat. The question is not whether AI can generate convincing fake media. It is whether we can build infrastructure fast enough to verify what is real.
- AI Watermarking Is Proactive: Unlike deepfake detection, which inspects files after the fact, watermarking injects a tracking signal at the exact moment of creation.
- SynthID Uses Three Separate Techniques: Pixel perturbation for images and video, tournament sampling for text, and spectral masking for audio. One approach cannot work across all media types.
- C2PA Metadata Is Easily Stripped: Social media platforms routinely remove file metadata during compression, severing the cryptographic verification chain entirely.
- The Integrity Clash Is the Underreported Risk: SynthID and C2PA can produce contradictory verdicts about the same file, and attackers are already exploiting this gap.
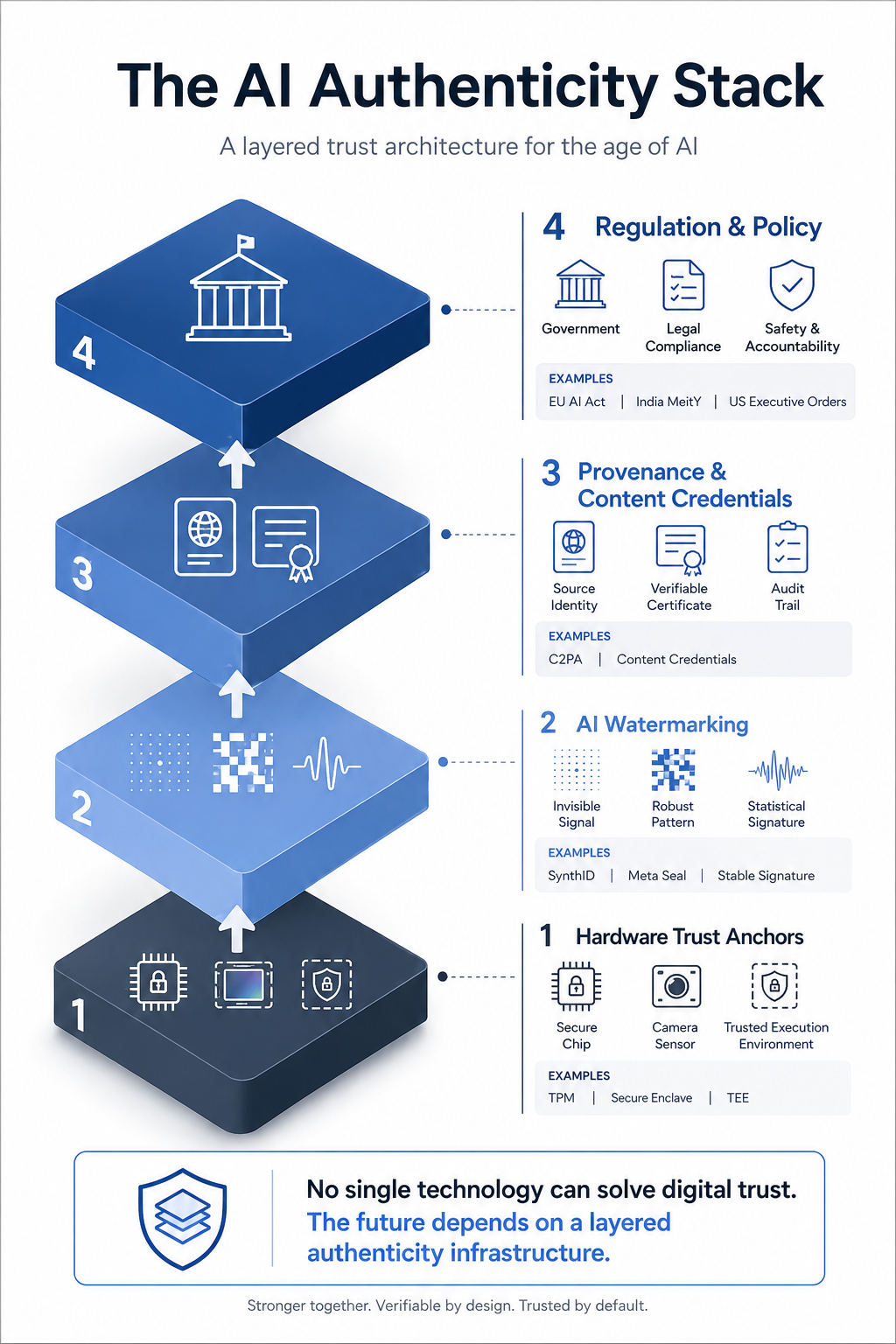
- No Single Technology Solves This: Digital trust requires a 4-layer stack combining hardware anchors, watermarking, cryptographic provenance, and regulation working together.
- The Internet's Authenticity Crisis
- What Is AI Watermarking
- How Google SynthID Works
- The Competitive Landscape
- Watermarking vs Deepfake Detection
- Can Watermarks Be Removed
- Content Credentials and C2PA
- When Two Truths Collide
- The AI Authenticity Stack
- Why Enterprises Should Care
- Regulation: The Guardrails
- The Future of AI Authenticity
The Internet's Authenticity Crisis
For most of the internet's history, a photograph, audio clip, or video carried an implicit burden of proof. Capturing a moment required physical presence. Synthetic media existed but was visually crude enough that trained eyes could spot the anomalies: artifacts at hairlines, unnatural blinking, hands with too many fingers.
That era is over. We have crossed an inflection point where generative AI has conquered the uncanny valley entirely. The flaws are gone. The cost to produce convincing fake media has dropped to near zero. And the scale of production has grown to industrial proportions.
The technology sector's response has been a fundamental paradigm shift: away from reactive tools that try to catch fakes after they spread, and toward a proactive trust infrastructure that verifies authenticity at the moment of creation.
What Is AI Watermarking
Unlike the visible copyright stamps on stock photography, an AI watermark is a hidden digital signature woven directly into the data structure of the asset. A human viewer cannot see or hear it. A verification algorithm can read it instantly.
Tracking signal is mathematically bound to the content itself. Cannot be removed without degrading the asset.
Trapped in a permanent arms race. Every new generation model renders existing detectors blind.
Traditional file attributes like EXIF metadata are trivially deleted when someone resaves or shares a file. AI watermarking fixes this by embedding the tracking signal into the pixels or token distribution themselves, so the identity of the content travels wherever the file goes.
Think of an AI watermark as an invisible serial number. It is not a label attached to the outside of the file. It is a mathematical property of the file's internal data. You cannot remove the serial number without altering the data it lives in.
How Google SynthID Works
Google built SynthID as a suite of specialized mathematical models rather than a single universal technique. This is because text, images, and audio have fundamentally different data structures. A single approach that works on pixels cannot work on discrete word tokens. SynthID's three core techniques each address this uniquely.
SynthID-Image and Video: Pixel-Space Perturbation
A common misconception is that SynthID modifies how an image is drawn by the diffusion model. In reality, SynthID-Image operates as a post-generation step.
The embedder applies a controlled, mathematical alteration to the pixel data that mimics natural camera sensor noise. Because the detector is trained alongside the embedder using adversarial machine learning, the watermark is conditioned to survive extreme edits including heavy JPEG compression, rotating, resizing, and color adjustments.
Because the watermark is mathematically tied to the image geometry, an attacker cannot strip the signature without severely altering the pixels, effectively destroying the image's visual value. The cost of removal exceeds the value of the tampered asset.
SynthID-Text: Tournament Sampling
Watermarking written text is significantly harder than images because words are discrete units. You cannot add noise to a word without changing its meaning. SynthID-Text solves this by intervening directly in the LLM's token selection process.
The final text reads naturally. No word is grammatically wrong. But the statistical distribution of word choices across the document carries a unique, cryptographically verifiable pattern that identifies the source model.
SynthID-Audio: Spectral Masking
For audio generated by models like Lyria, SynthID converts sound waves into a visual frequency chart called a spectrogram. It then leverages human psychoacoustic masking, the natural quirks of how humans process sound, to weave the watermark into specific frequency bands. The audio sounds pristine to human ears but the watermark survives format changes and MP3 compression.
The Competitive Landscape
Google is not alone. Other major AI labs are actively deploying competing frameworks, each with different architectural choices.
| Company | Approach | Key Technique | Distinctive Feature |
|---|---|---|---|
| Google DeepMind | SynthID Suite | Pixel perturbation, tournament sampling, spectral masking | 10B+ images watermarked; planet-scale deployment |
| Meta | Pixel Seal + Stable Signature | Adversarial training; watermark embedded in latent decoder weights | Open-source; every generated image carries watermark from birth via model weights |
| OpenAI | Cryptographic PRF + C2PA | Pseudorandom function biases n-gram sequences; metadata credentials for images | Dual-layer: invisible text watermark plus visible content credentials |
Meta's Stable Signature approach is architecturally distinct: rather than applying watermarks after generation, the signature is rooted directly within the mathematical weights of the model's latent decoder. Every image the model generates automatically carries the watermark as a structural property of the generation process itself.
Watermarking vs Deepfake Detection
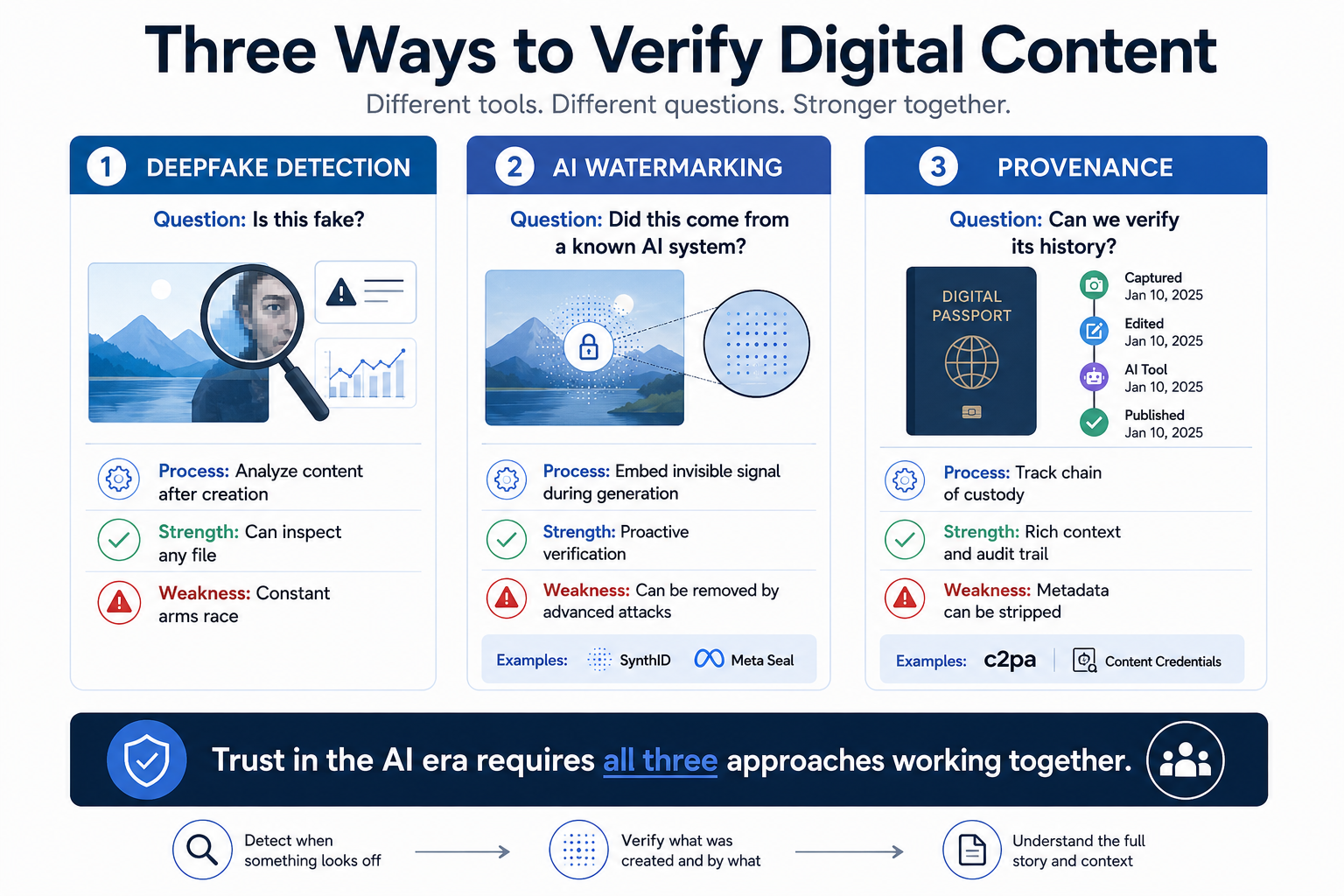
| Feature | AI Watermarking | Deepfake Detection |
|---|---|---|
| Core Question | Did this file come from a known AI system? | Is this specific file authentic or fake? |
| Approach Type | Proactive: injects signal at creation | Reactive: inspects file after the fact |
| Primary Strength | Near-perfect accuracy if signal is intact | Can analyze any file, even from non-watermarked systems |
| Primary Weakness | Only works if the developer chose to include it | Becomes blind when new generation models launch |
| Arms Race Risk | Low: does not depend on output flaws | High: permanent cat-and-mouse with model improvements |
Can Watermarks Be Removed
Adversaries can bypass watermarks using three primary methods. Understanding these attack vectors is essential for designing systems that do not over-rely on any single protection layer.
Security researchers including Hany Farid at UC Berkeley have consistently noted that watermarking alone cannot serve as a comprehensive defense against sophisticated deepfakes. The academic consensus is that imperfect watermarks still provide significant value by raising the cost of abuse for the majority of bad actors: casual fraudsters and automated bot networks lack the resources to conduct differentiable surrogate attacks at scale. The goal is not perfect protection. The goal is to neutralize mass-scale automated fraud.
Content Credentials and C2PA
Spearheaded by a coalition including Adobe, Microsoft, and major news networks, Content Credentials provide a verified breakdown of a media file's origins. When viewing a C2PA-compliant image, a user can inspect a complete audit trail: the capture device, every editing tool applied, and full AI disclosure.
The primary flaw is structural. C2PA manifests live in the file's metadata container. When a file is uploaded to most social media platforms, the platform strips metadata during compression. The cryptographic verification chain is severed entirely. The content credential disappears before it can be read.
| Metric | SynthID (Watermarking) | C2PA / Content Credentials |
|---|---|---|
| Data Location | Inside the file's pixels or token distribution | Attached to the file's metadata container |
| Data Payload | Low: simple origin flag (AI or not) | High: creator ID, edit logs, device details, AI disclosure |
| Screenshot Resistance | High: signal lives inside pixels, survives screenshots | Zero: screenshot destroys the metadata container |
| Social Media Resistance | High: adversarially trained to survive compression | Low: stripped by platform compression pipelines |
| Verification Method | Requires proprietary API or key from developer | Open-source parsers and public viewer tools |
When Two Truths Collide

The attack works as follows. A malicious user takes an AI-generated image that carries an invisible SynthID pixel watermark. They run it through a C2PA-compliant editor, such as Adobe Photoshop, and apply a minor color correction. The editor issues a fresh, cryptographically valid C2PA manifest asserting human authorship over that edit.
The asset now exists in an authenticated contradiction. The visible C2PA metadata proves a human edited it. The underlying pixels flag it as synthetic. Both verdicts are backed by cryptographic signatures. Neither is technically wrong. Resolving this requires verification infrastructure that consults both layers simultaneously and flags conflicts as inherently suspicious.
The AI Authenticity Stack
By stacking these technologies, each layer compensates for the structural flaws of the others. If an attacker strips the C2PA metadata, the SynthID pixel watermark remains. If an attacker corrupts the image geometry to break the watermark, the visual fidelity is destroyed. If both software layers are compromised, hardware-anchored signatures remain. Regulation enforces the entire stack through legal liability.
Why Enterprises Should Care
- Corporate Fraud and Executive Impersonation: Synthetic voice cloning and video deepfakes of executives ordering fraudulent wire transfers are already in production use by threat actors. Without provenance verification, companies cannot definitively authenticate internal directives.
- Legal and Copyright Exposure: Enterprises using generative AI tools without proper tracking mechanisms risk severe liabilities when un-watermarked assets inadvertently infringe on copyrighted material or violate disclosure regulations.
- Loss of Safe Harbor: Under new global legislation, platforms that fail to deploy synthetic media detection and comply with takedown timelines lose their intermediary liability protections and become directly liable for user-uploaded deepfakes.
Regulation: The Guardrails
Regulation moves the liability burden from content creators to platforms. The legal question is no longer whether synthetic media caused harm, but whether the platform had deployed reasonable detection infrastructure before the harm occurred. Safe-harbor protections are becoming contingent on technical readiness, not just policy intent. Platforms that treat watermark detection as a future roadmap item rather than a current compliance requirement are accumulating legal exposure today.
The Future of AI Authenticity
The technological arms race between deepfake synthesis and content verification will continue to escalate. Researchers expect this evolution to unfold across three clear horizons.
Regulatory pressure is likely to push the siloed landscape of proprietary watermarks toward convergence. Platforms may adopt unified detection APIs capable of cross-referencing C2PA manifests with multiple watermark standards simultaneously. Text watermarking could shift toward semantic embedding partitions, making signatures more resilient to heavy rewriting attacks.
Software-based tracking may increasingly hand enforcement to hardware. Trusted Execution Environments built directly into consumer devices and professional camera processors could become more common. If that trajectory holds, provenance might be cryptographically anchored at the exact moment of capture, making source authentication a hardware-level property rather than a software assertion.
The longer-term possibility is that generative model architectures get restructured at a deeper level. Future multimodal models could be designed with watermarking as a built-in constraint rather than an add-on, making it significantly harder to produce synthetic content without an embedded signature. Whether this becomes industry standard depends heavily on how regulation and incentives evolve over the next decade.
From Reactive Guessing to Engineered Trust
The early response to AI-generated media treated authenticity as a detection problem. The assumption was that if we could build better detectors, we could reliably distinguish real content from synthetic content after it had already been created and distributed. That approach is rapidly reaching its limits. As generative models produce text, images, audio, and video that are increasingly indistinguishable from reality, the challenge is no longer detecting every fake after the fact.
Instead, the industry is shifting toward a fundamentally different model: building trust directly into the content ecosystem itself. Invisible watermarks can persist across distribution channels, cryptographic provenance systems can record how content was created and modified, hardware-based trust anchors can establish authenticity at the point of capture, and regulatory frameworks can create accountability across the entire chain. Together, these technologies form a layered foundation for verifying digital content at internet scale.
The next era of the internet will not be defined by our ability to identify deception after it appears. It will be defined by our ability to establish trust before deception takes hold. The objective is shifting from identifying what is fake to making what is real verifiable.