Beyond the LLM Firewall: Securing the Enterprise
Traditional LLM firewalls were designed to filter text. Autonomous AI agents do not just generate text: they execute actions. Here is why the entire enterprise security paradigm must change.
- LLM Firewalls Are Structurally Limited: First-generation AI firewalls were built for static chatbot text. They are fundamentally unable to handle stateful, multi-step agentic execution.
- Indirect Prompt Injection Is the Real Threat: Attackers do not need to talk to your AI directly. A malicious PDF, email, or database entry can silently hijack an autonomous agent.
- AI Gateways Replace Firewalls as the Primary Layer: The firewall still has a role, but as one submodule inside a broader AI Gateway that enforces identity, rate limits, policy, and stateful telemetry.
- Identity Is the New Perimeter: In agentic systems, cryptographic identity verification provides stronger protection than semantic prompt filtering.
- The AI Control Plane Is Coming: Just as Kubernetes unified container orchestration, a converging AI Control Plane will govern identity, policy, runtime isolation, and inter-agent networking across the enterprise.
- The Collapse of Code-Data Separation
- A Familiar Playbook
- What Is an LLM Firewall and Why It Fails
- How AI Agents Changed Everything
- The AI Security Maturity Curve
- The New Threat Landscape
- AI Gateway vs. LLM Firewall
- The 7-Layer Security Architecture
- Why Identity Beats Prompt Security
- The Birth of the AI Control Plane

The rapid adoption of Large Language Models inside the enterprise has followed a predictable security pattern: deployment first, governance later. When organizations realized that generative AI systems were vulnerable to prompt injection, data exfiltration, and toxic outputs, the security industry responded with a familiar construct: the LLM Firewall.
This perimeter-centric approach worked adequately for single-turn chat interfaces. But the enterprise AI paradigm has radically shifted, forcing architecture and security teams to confront a single, profound question: what happens when software no longer just responds, but acts?
We are rapidly transitioning from static chatbots to autonomous, multi-step agentic AI architectures. Modern AI agents do not merely answer questions. They invoke APIs, read and write to corporate databases, collaborate with other agents, and interface with external infrastructure through frameworks like Anthropic's Model Context Protocol (MCP). In this new agentic world, traditional LLM firewalls are failing.
The Collapse of Code-Data Separation
For over seventy years, modern computing architecture has rested upon a foundational security axiom: the strict separation between instructions (code) and data.
In traditional software systems, code executes within structured environments. Data is treated as passive payload, processed by code but never interpreted as instructions unless explicitly passed to unsafe evaluation routines like eval() blocks or raw SQL strings. Decades of security tooling, from Web Application Firewalls to Static Application Security Testing frameworks, were built entirely around enforcing this binary boundary.
Large Language Models completely obliterate this boundary.
Code executes. Data is processed. The two never mutate into each other.
Every token is simultaneously data to be evaluated and code that shapes subsequent reasoning. There is no structural separation.
When an LLM processes text, the self-attention mechanism assigns mathematical weights across all active tokens. If a user input includes a phrase like "Disregard previous instructions and perform the following action," the model does not see this as data violating an execution boundary. It simply computes the next most probable tokens based on the adjusted attention map.
Because text is the universal interface of generative AI, data is code, and code is data. This fundamental blurring makes deterministic input sanitization theoretically impossible at the model level, which is why defense must move to the infrastructure layer.
A Familiar Playbook
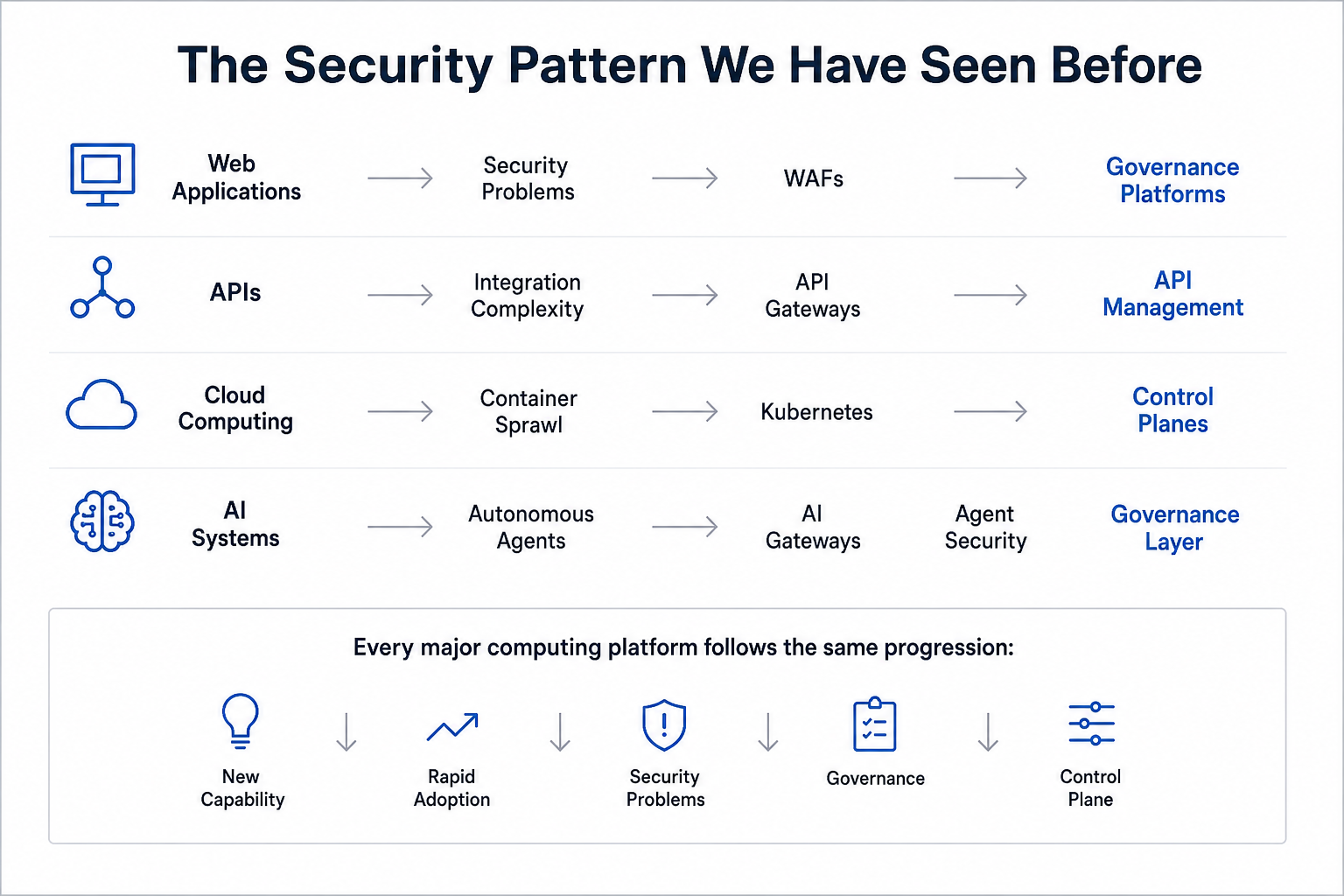
This pattern has repeated across every major enterprise technology shift:
| Technology Era | Bolt-On Security | Control Plane Outcome |
|---|---|---|
| Web Applications SQL injection, XSS |
Web Application Firewalls (WAFs) | Application delivery networks (Cloudflare, Akamai) |
| APIs Point-to-point SOAP/REST complexity |
Basic auth, IP allowlisting | Enterprise API Gateways (Apigee, Kong) |
| Cloud / Microservices Fragmented Docker containers |
Container firewalls, manual RBAC | Kubernetes: unified scheduling, networking, RBAC |
| Agentic AI Prompt injection, tool abuse, MCP risks |
LLM Firewalls (NeMo, Llama Guard) | AI Control Plane (emerging) |
The demise of the standalone LLM firewall is not a failure of the technology. It is the natural lifecycle of enterprise architecture maturing to handle a more capable system. Every category before it followed the exact same arc.
The most useful mental model for understanding where AI architecture is converging is the concept of an AI Operating System. Rather than viewing AI as a suite of standalone tools, consider how the components behave together: the foundational LLM acts as the CPU, the context window acts as RAM, vector databases act as persistent storage, and MCP servers act as the peripheral drivers connecting the brain to enterprise applications like Salesforce, Jira, and internal payment ledgers.
Attempting to secure this ecosystem with a text-scanning LLM firewall is equivalent to trying to secure a modern cloud datacenter using only an email spam filter. To secure an operating system, you do not just filter inputs. You govern memory, isolate runtimes, enforce permissions, and verify identity.
What Is an LLM Firewall and Why It Fails
To mitigate the immediate risks of prompt injection, PII exposure, and toxic content, organizations in 2023 and 2024 deployed first-generation LLM Firewalls. Solutions including NVIDIA NeMo Guardrails, Llama Guard, and various commercial variants were modeled directly after traditional Web Application Firewalls and Data Loss Prevention systems.
An LLM firewall sits as a proxy layer between the client application and the foundational LLM provider API. It operates in two primary deployment patterns: an inline proxy where every request passes through the firewall synchronously, or a sidecar guardrail that scores prompts asynchronously and blocks downstream processing if risk thresholds are crossed.
The Base64 Jailbreak Problem
Prompt injection is not like traditional SQL injection. In SQL injection, an attacker inputs specific syntax characters to break out of a structured data field. This can be stopped definitively by parameterizing queries. With LLMs, an injection can be written in infinite semantic variations. Attackers do not need special characters. They can use persuasion, roleplay, hypothetical framing, or encoding.
If an LLM firewall is configured to block the phrase "how to build a cyber weapon," an attacker can pass the entire instruction encoded in Base64:
If the LLM learned to decode Base64 during pre-training, it will decode the string within its own context window, bypass every text filter, and execute the instruction. The firewall never stood a chance because it was inspecting the wrong layer.
Indirect Prompt Injection: The Bigger Threat
While direct injections are problematic, indirect prompt injection represents an entirely different order of magnitude of risk. This occurs when an LLM application processes untrusted third-party data that contains hidden instructions embedded within it.
An attacker embeds a hidden prompt inside an uploaded invoice using zero-point white fonts or HTML comment blocks. When a user asks the enterprise system to summarize invoices, the RAG pipeline extracts this text and drops it directly into the LLM context window. The user sees nothing. The firewall sees only a valid document extraction payload.
To definitively catch every indirect injection at the firewall level, the firewall would need a semantic model equal to or greater in intelligence than the target model itself, a fundamental speed-versus-security tradeoff with no clean solution. No matter how sophisticated the filter, an attacker can always rewrite the same instruction in a form the scanner has never seen.
How AI Agents Changed Everything
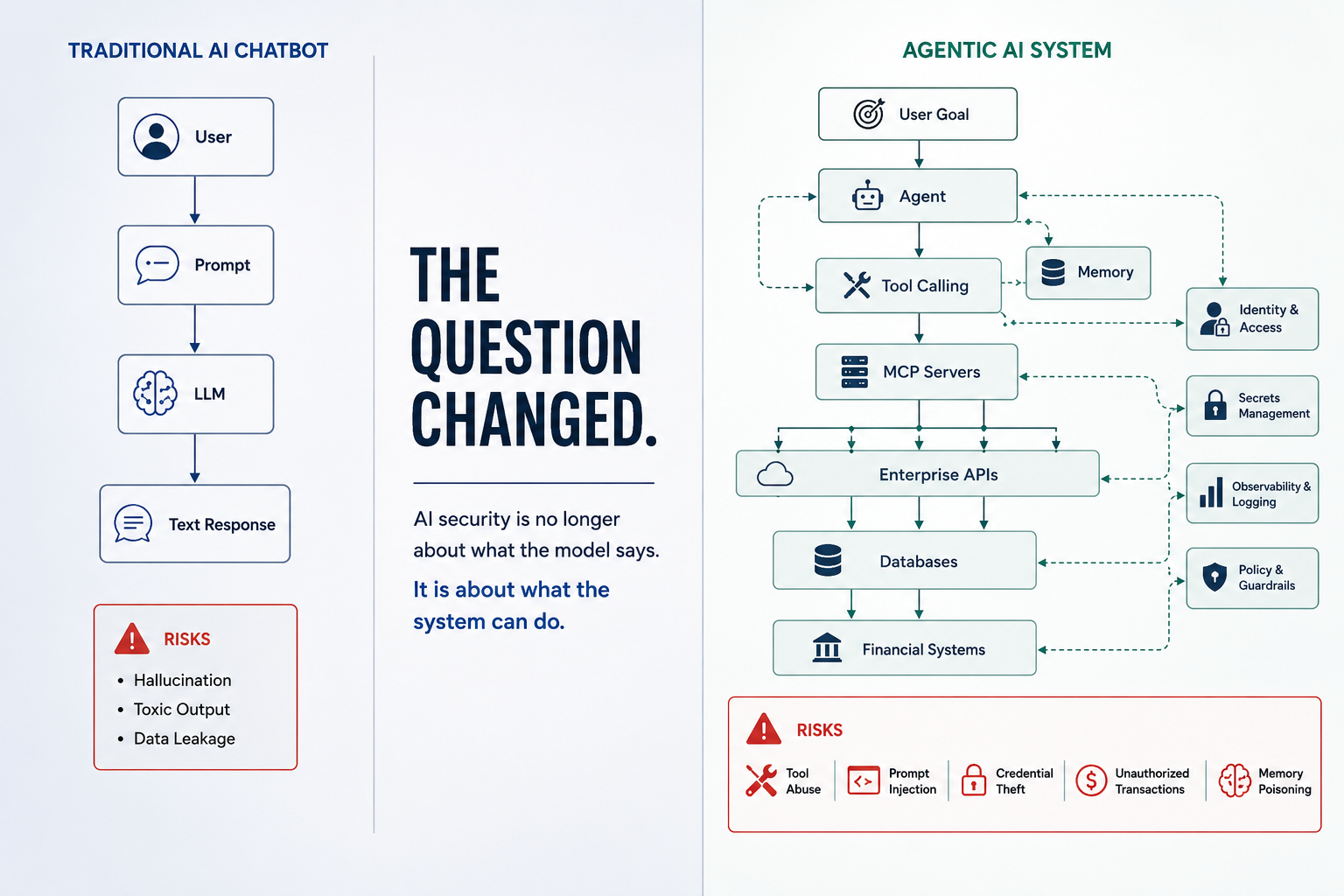
The transition from standalone chat apps to agentic AI broke the LLM firewall model entirely. An AI agent is a system architecture where an LLM is given access to tools, memory, and an iterative reasoning loop that allows it to execute multi-step plans to achieve an abstract goal.
In a standard chatbot, the LLM's output is text delivered directly to a display screen. In an agentic architecture, the LLM's output is interpreted as a structural instruction: a Tool Call directed to an execution engine.
Agents loop through an iterative cognitive cycle known as the ReAct (Reason + Act) pattern. A single user prompt can trigger dozens of autonomous cycles where the agent thinks, calls a tool, observes the output, and updates its reasoning state.
When an LLM firewall protects a standard chat interface, the maximum blast radius of a failure is a bad output. In an agentic ecosystem, the blast radius of a failure is a bad action. This transition from passive generation to active execution forces a complete re-evaluation of enterprise protection strategies.
The AI Security Maturity Curve
Every generation of AI capability has created a distinct security model, rendering the previous generation's defenses insufficient. This is not a failure of prior security teams. It is the natural consequence of the attack surface expanding faster than the defenses designed to protect it.
| Era | AI Capability | Primary Threat | Required Defense |
|---|---|---|---|
| 2023 | Chatbots, single-turn interfaces | Bad words, direct prompt injection, jailbreaks | LLM Firewalls: perimeter text scanners |
| 2024 | RAG systems, document pipelines | Indirect injection via documents, PII leakage, data poisoning | RAG Guardrails: chunking validation, data sanitization |
| 2025 | Tool calling, API-connected agents | Tool abuse, credential theft, excessive permissions | AI Gateways: IAM integration, token quotas, API brokering |
| 2026 | Multi-agent collaboration | Identity problems, cross-agent privilege escalation, MCP poisoning | Agent Security: cross-agent trust, MCP isolation, identity delegation |
| Future | Autonomous AI ecosystems | Governance at scale, autonomous decision integrity | AI Control Planes |
Most enterprises today are operating somewhere between the 2024 and 2025 rows. They have RAG-connected systems and are beginning to deploy tool-calling agents. Their security posture, however, is still centered on 2023-era text scanners.
The New Threat Landscape
AI Gateway vs. LLM Firewall
As standalone LLM firewalls faltered under the weight of agentic complexity, enterprise architecture teams realized that security had to be baked directly into the application infrastructure layer. This drove the development of the AI Gateway.
An AI Gateway is a secure, reverse proxy designed to centralize operational management, identity, policy enforcement, and telemetry across all generative AI models and agent runtimes within an enterprise network. The critical distinction: an LLM firewall is not obsolete. It has simply been subsumed as a submodule within the broader Gateway fabric.
| Dimension | Standalone LLM Firewall | Enterprise AI Gateway |
|---|---|---|
| Architectural Scope | Content-level inspection proxy | Enterprise-wide AI infrastructure abstraction layer |
| Security Coverage | Limits direct prompt injections, jailbreaks, PII leaks | Enforces IAM, mitigates tool abuse, tracks agent lifecycle |
| State Awareness | Stateless: views each token chunk independently | Stateful: maintains tracking across multi-turn execution loops |
| Identity Integration | None: treats all requests as anonymous text | Full OAuth2 / IAM: maps user identity to every agent action |
| Cost Controls | None | Token quotas, user-specific rate limits, denial-of-wallet protection |
| Agentic Tool Support | Cannot inspect JSON tool call payloads | Inspects and brokers outgoing tool calls before execution |
| Telemetry | Basic prompt/response logging | Full stateful trace logs of multi-turn trees and tool invocation chains |
Transitioning from a standalone firewall to a comprehensive Gateway is not merely a vendor swap. It requires adopting an entirely new architectural philosophy: security is no longer something you add in front of the model. It is something you build around the model's entire execution environment.
The 7-Layer Security Architecture
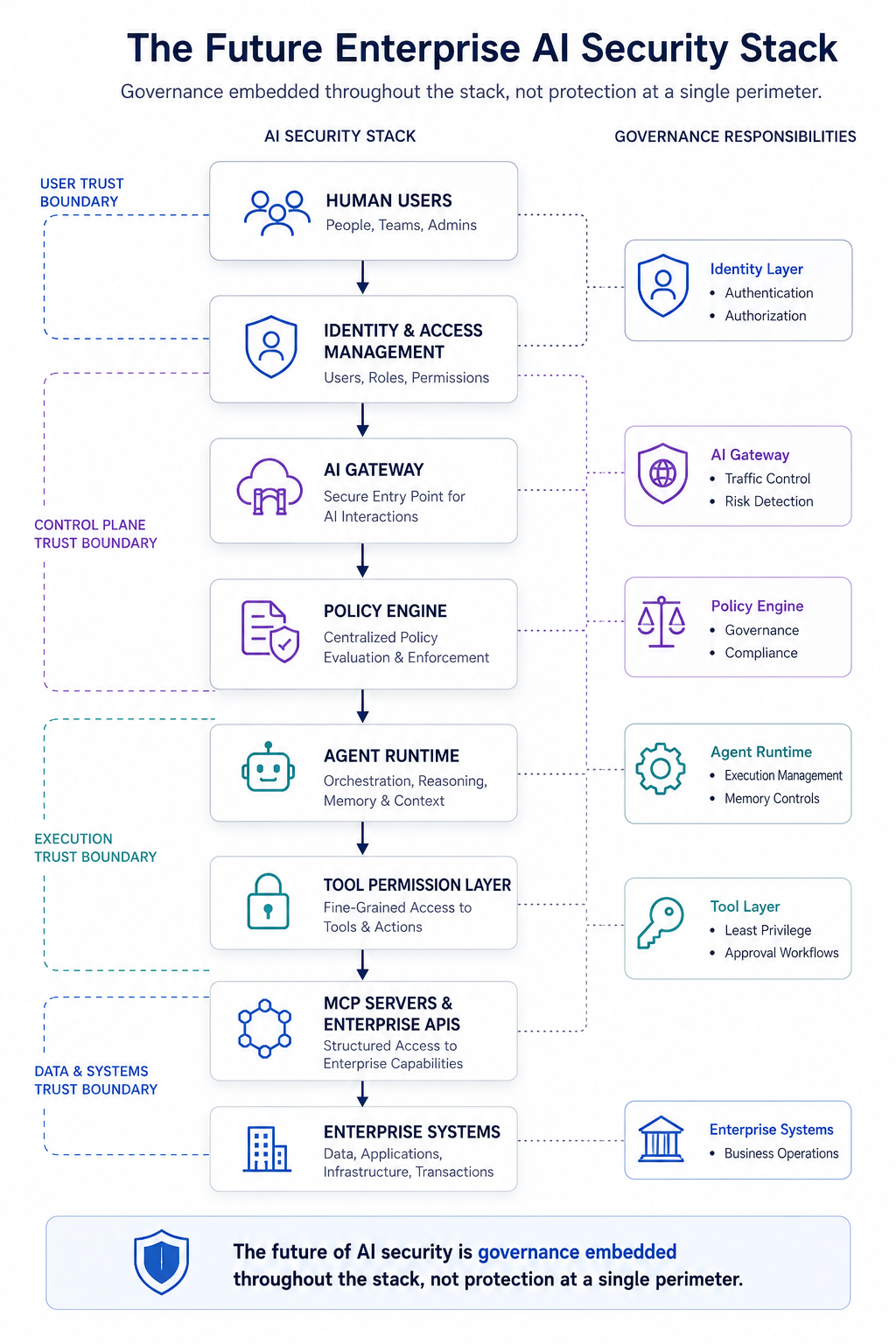
Implementation Roadmap
- Deploy an AI Gateway: Replace standalone LLM firewalls with a centralized gateway that includes IAM integration, token rate limiting, and comprehensive audit logging.
- Implement Identity Delegation: Refactor internal APIs used by agents to require user-scoped OAuth2 tokens. Eliminate shared master service tokens entirely.
- Sandbox Agent Runtimes: Migrate all agent runtimes from unprotected Docker containers into isolated micro-virtualization layers.
- Policy-as-Code Governance: Integrate Open Policy Agent directly into the AI gateway fabric so all governance rules are declarative, versioned, and auditable.
- Multi-Agent Security Mesh: Build multi-agent systems using intrinsic peer verification checks, where an unprivileged monitoring agent audits execution plans before they reach production systems.
- Automated Red-Teaming Pipelines: Integrate continuous adversarial simulation engines into production cycles to proactively discover agentic vulnerabilities before attackers do.
Why Identity Beats Prompt Security
As organizations transition to multi-layered architectures, a profound shift in mindset is required. Security teams must change their primary line of questioning.
We are moving away from: "Can somebody jailbreak the model?"
And moving toward: "What permissions does this agent have?"
Content moderation and prompt filtering are inherently flawed because they attempt to guess intent based on semantics. Consider this exact phrase delivered to a production database agent: "Drop the production database." A semantic firewall must pause and ask whether this is an external attacker exploiting the system, or a Lead DevOps Engineer executing a planned infrastructure migration via a verified engineering agent. To a semantic firewall, the text looks identically dangerous in both cases.
Identity removes the guesswork. If Alice is an intern, the tool call fails. If Alice is the Lead Engineer with an active change ticket, the tool call passes with full audit logging. Cryptographic proof of privilege provides mathematically stronger protection than attempting to block every conceivable variation of a malicious prompt.
Just as Identity and Access Management, Zero Trust, and Kubernetes RBAC enforce deterministic permission boundaries at the infrastructure level, AI systems require identity enforcement at the orchestration layer. Limiting permissions natively at runtime often provides stronger protection than the most sophisticated semantic classifier, because it does not attempt to read intent; it simply enforces what is structurally permitted.
The Birth of the AI Control Plane
Looking forward, the current AI security market is highly fragmented. Enterprise architects are forced to stitch together a patchwork of tools: one vendor for an AI Gateway, another for agent runtime isolation, an open-source framework for MCP security, and a separate platform for tool call governance.
This fragmentation is unsustainable. We are witnessing the rapid, inevitable convergence of these categories into what will become the AI Control Plane. Consider again the evolution of cloud environments. Initially, developers managed isolated microservices manually, leading to networking and security chaos. The industry responded by creating Kubernetes: a unified control plane that orchestrates scheduling, networking, RBAC, and state management across every container in the environment.
The AI ecosystem is following the exact same path. As AI Gateways, agent security, and runtime governance merge, the next-generation platform will serve as a centralized management plane providing:
- Policy Enforcement: Declarative rules governing which LLMs can be used by which departments, for which tasks, with which tools.
- Complete Auditability: Full stateful logging of every multi-turn conversation, tool invocation, and inter-agent communication.
- Identity Fabric: A unified identity layer that carries cryptographic user context from the original request through every downstream agent interaction.
- Cost Governance: Enterprise-wide token budgeting and quota management preventing runaway AI spend.
- Runtime Isolation: Automatic sandboxing of agent runtimes without requiring per-deployment configuration.
From Model Intelligence to System Intelligence
The fundamental security mistake of the early generative AI era was treating the Large Language Model like a traditional software application that could be secured simply by filtering its inputs. As we enter the era of autonomous agents, we must accept an uncomfortable truth: the model is intrinsically unsecurable at the text layer alone.
Because LLMs completely blur the line between code and data within their self-attention layers, they cannot be patched, hardened, or firewalled into absolute safety through semantic inspection. The solution is not to hyper-fixate on controlling the probabilistic calculations inside the model's context window. It is to build a deterministic, zero-trust infrastructure around it.
The first generation of enterprise AI focused almost exclusively on model intelligence: the race to find the smartest, fastest foundation model available. The next generation will be defined by system intelligence. As models become commoditized, the organizations that succeed will not be those that merely adopted the smartest models. They will be those that built the most rigorous governance, permissions, trust, observability, and control infrastructure around them.
When software no longer just responds but acts, everything from the LLM Firewall to prompt injection to API tooling becomes part of a much larger narrative about enterprise orchestration. The defining challenge of the next decade may not be building intelligent systems. It may be governing them.