DiffusionGemma Explained: How Text Diffusion Breaks the LLM Memory Wall
Google DeepMind's experimental model abandons sequential generation for parallel discrete diffusion, hitting 700+ tokens per second on consumer hardware.
Natural language generation has been dominated by the autoregressive transformer for years. Every model you have ever interacted with (GPT-4, Claude, Gemini, Llama) generates text the same way: one token at a time, strictly left to right. This architecture achieves remarkable fluency, but it hides a deep hardware limitation that becomes especially painful when running models locally.
During single-user inference, traditional LLMs are dramatically throttled by memory bandwidth. The GPU's tensor cores, which execute the actual matrix math, sit idle up to 90% of the time, starved for data while weights are ferried from VRAM. To break this constraint, Google DeepMind introduced DiffusionGemma: a 26-billion-parameter model that abandons sequential prediction entirely in favor of parallel discrete text diffusion. Instead of printing tokens one by one like a typewriter, it generates an entire block of text simultaneously, refining it like a photo editor working on a rough draft.
The result: local generation speeds exceeding 700 tokens per second on consumer GPUs, and over 1,000 tokens per second on enterprise accelerators.
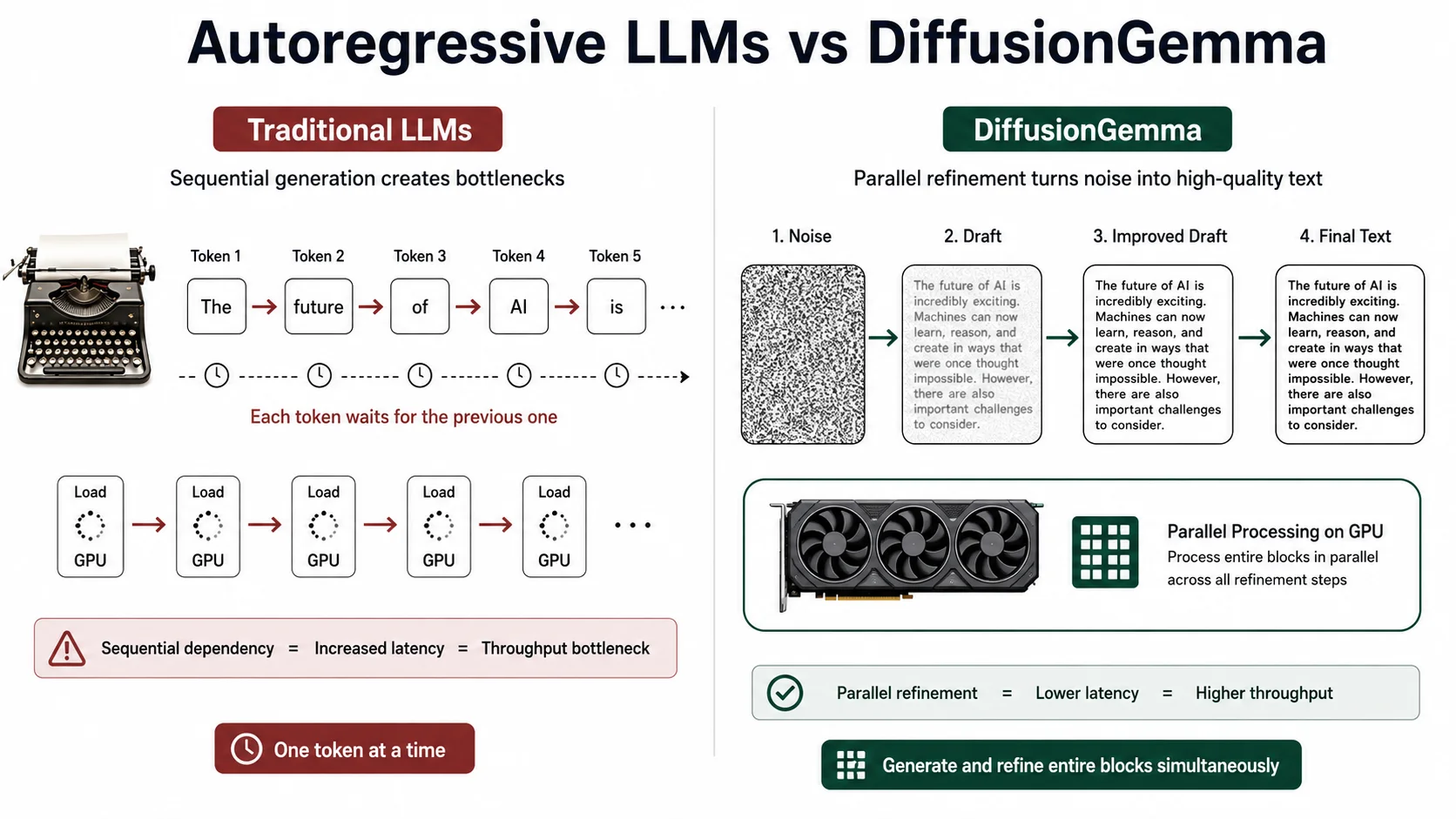
DiffusionGemma shifts inference from memory-bandwidth-bound sequential generation to compute-bound parallel refinement.
- The Memory Wall: autoregressive LLMs load tens of gigabytes of weights for every single token generated, leaving GPU compute cores idle up to 90% of the time.
- Discrete diffusion: DiffusionGemma initializes a full 256-token block simultaneously and refines it in parallel passes using bidirectional attention, shifting the bottleneck from memory bandwidth to raw compute.
- Speed without full parity: 700+ tokens/sec locally, but measurably lower zero-shot reasoning scores on math and logic benchmarks versus standard autoregressive models.
- Best for: code infilling, structured JSON routing, offline privacy-critical applications, and any workload that needs structural consistency over sequential reasoning chains.
The Memory Wall: Why Autoregressive LLMs Are Slow
When an autoregressive transformer generates text, it operates in a strict loop: read the prompt, predict the next token, append it to the history, and restart. For a single user running a model locally, this creates a severe engineering challenge known as the Memory Wall.
Every time the model generates a word, the GPU fetches its entire set of weight parameters from video RAM and loads them into local compute registers. For a 26-billion-parameter model, the hardware moves tens of gigabytes of data across the silicon bus just to yield a single token. Because modern tensor cores execute matrix math significantly faster than the hardware can stream data, the GPU's processing units sit idle up to 90% of the time, waiting for memory rather than running out of compute.
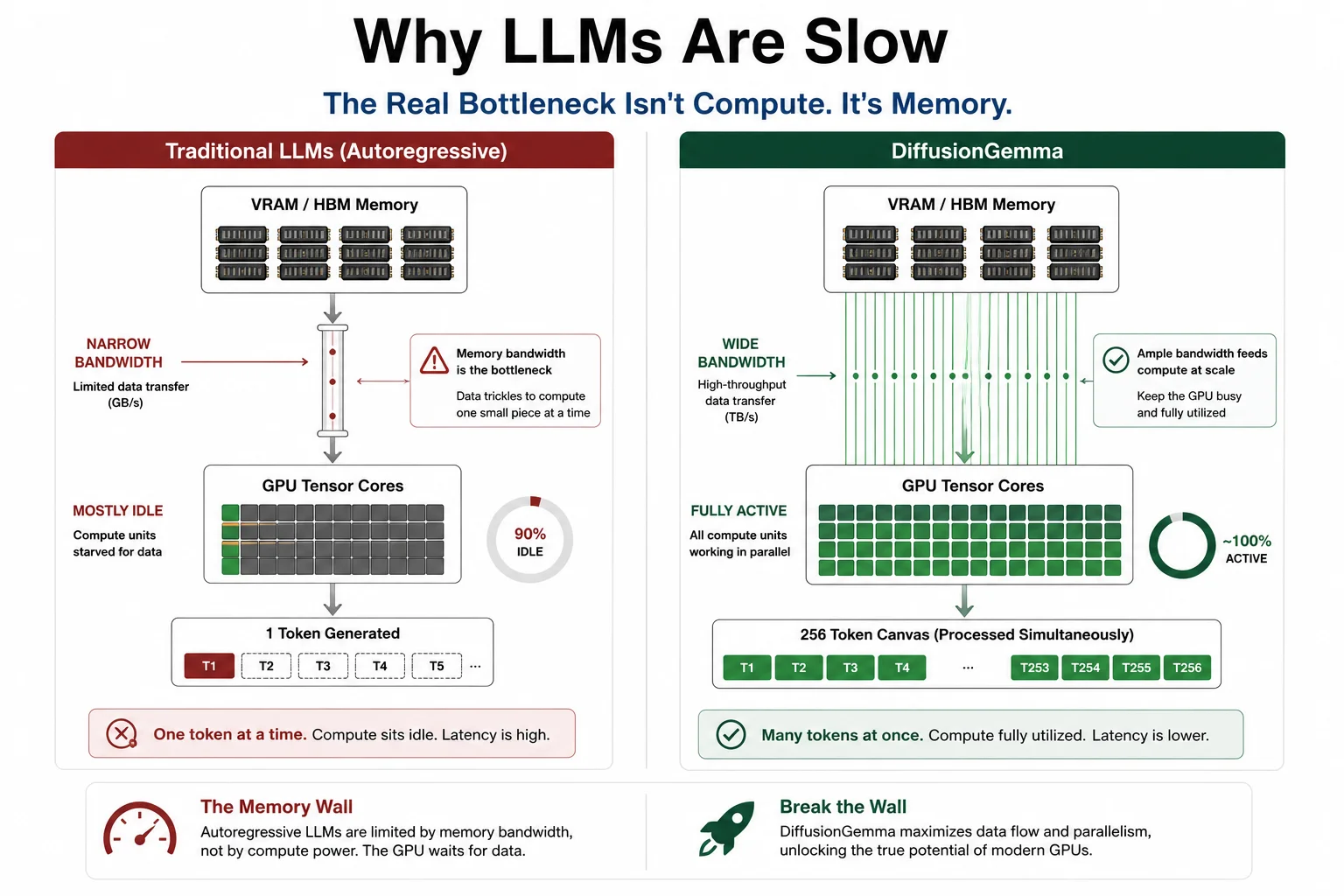
The autoregressive typewriter loop: the same weights travel across the memory bus for every single token generated, leaving compute cores starved for data.
- Token 1 → Load 26B weights from VRAM → Predict Token 2
- Token 2 → Load 26B weights from VRAM → Predict Token 3
- Token 3 → Load 26B weights from VRAM → Predict Token 4
Each step is memory-bound. TFLOPS sit unused while the bus saturates moving data.
The Reversal Curse
Beyond hardware latency, sequential generation introduces a cognitive flaw called the reversal curse. Because autoregressive models are trained to predict text exclusively left to right, their internal knowledge is highly directional. If a model learns the factual sequence "A is the mother of B," it will frequently fail to resolve the inverted query "Who is B's mother?" Causal attention masks physically prevent the network from looking forward during training, restricting its capacity to resolve symmetrical relationships natively.
Enter DiffusionGemma
DiffusionGemma is a 26-billion-parameter Mixture-of-Experts (MoE) discrete diffusion language model built directly on the Gemma 4 backbone. Instead of predicting words sequentially, it initializes an entire block of text simultaneously and refines it iteratively, treating generation like a photo editor polishing a rough draft rather than a typewriter printing a page.
Because it processes the full block in parallel, the weights are loaded once per refinement pass and applied across 256 tokens simultaneously. This shifts the inference bottleneck from memory bandwidth to raw computational throughput, turning the Memory Wall into a non-problem for single-user workloads.
Model Architecture at a Glance
| Specification | Value | Why it matters |
|---|---|---|
| Total Parameters | 25.2 Billion | Built on the Gemma 4 26B-A4B backbone; the full weight set stored in VRAM. |
| Active Parameters per Token | 3.8 Billion | MoE routing fires only 3.8B per token, so inference runs at roughly the speed of a 4B dense model despite the 26B footprint. |
| Total Experts | 128 | The router selects from 128 specialized sub-networks each forward pass. |
| Active Experts per Token | 8 + 1 shared | 8 specialized experts handle routing; the always-on shared expert acts as a dense layer to preserve global context across decisions. |
| Layers | 30 | Transformer depth; shallower than comparable dense models, compensated by expert width. |
| Vocabulary Size | 262,144 tokens | Exact token count; the large vocab improves multilingual coverage and reduces tokenization fragmentation. |
| Vision Encoder | ~550M parameters | Retained from the 26B backbone (dropped in the 12B variant); supports variable resolutions and video frames up to 60 s at 1 fps. |
| VRAM (FP8 / NVFP4 quantized) | 18 – 24 GB | Fits a 24 GB consumer GPU like the RTX 5090 with headroom for the OS and the 256K context window. |
When quantized to FP8 or NVIDIA's 4-bit floating-point format, DiffusionGemma fits comfortably within the VRAM of consumer GPUs like the RTX 4090 and 5090, making full local deployment practical without specialized server hardware.
How Discrete Text Diffusion Works
Image diffusion models start with a clean picture, progressively corrupt it with Gaussian noise, and train a network to reverse that corruption. Applying this directly to language fails: there is no smooth mathematical midpoint between the words "cat" and "dog." Language is discrete and categorical, not continuous.
DiffusionGemma bypasses this by adopting Discrete Denoising Diffusion Probabilistic Models (D3PM). Instead of adding fuzzy visual static, D3PM defines a precise transition matrix over vocabulary tokens, a probability rulebook dictating exactly how likely each token is to mutate at any given step. DiffusionGemma uses the Absorbing State (Masking) strategy:
During training, words are randomly replaced by a [mask] token. The model learns to run this loop in reverse: starting from a fully masked sequence, it uses bidirectional attention, looking both forward and backward simultaneously, to predict all missing tokens at once. Because the attention mechanism has global context from the start, it resolves relational dependencies symmetrically, eliminating the reversal curse entirely.

Discrete diffusion in reverse: starting from full noise, the model refines a 256-token block in parallel passes until the text converges.
DiffusionGemma does not run a fixed number of denoising steps. Its entropy-bound sampler halts as soon as the canvas becomes mathematically stable:
- Temperature schedule: starts at 0.8 for broad semantic exploration, scales down to 0.4 to lock in final selections.
- Entropy filtering: tokens the model is certain about are locked in permanently; uncertain tokens are re-noised and re-evaluated in the next pass.
- Early stopping trigger: generation halts when average canvas entropy drops below 0.005 and two consecutive passes yield identical predictions. For structured tasks like code or JSON, this often happens in just 12 to 16 steps.
The Block Autoregressive System
Pure diffusion over open-ended sequences suffers from quadratic computational scaling, rapidly depleting memory. DiffusionGemma solves this with a Block Autoregressive Multi-Canvas Sampling paradigm. Text generation is divided into fixed 256-token blocks called "canvases," processed through two alternating modes:
The model runs standard left-to-right causal attention. It ingests the user prompt (or a completed canvas) and stores it in the Key-Value cache, which acts as a persistent historical clipboard. Once a 256-token canvas is fully denoised, the encoder mode runs again to commit that finalized block into the historical KV cache for future canvases to reference.
The model switches to bidirectional attention. A new 256-token canvas is populated with placeholder noise. Every token on this canvas attends to every other token simultaneously, while also extracting committed historical context from the KV cache. Parallel refinement passes run until the entropy-bound sampler declares convergence.
Production Serving Inside vLLM
Integrating a discrete diffusion model into an enterprise inference engine built for sequential serving is notoriously difficult. The vLLM maintainers achieved day-zero integration for DiffusionGemma by utilizing the ModelState API and reusing the existing Speculative Decoding infrastructure.
Normally, speculative decoding evaluates a batch of draft tokens all at once. vLLM simply treats DiffusionGemma's entire 256-token canvas as a massive draft block. During intermediate denoising steps, the sampler flags canvas tokens as "rejected," instructing the vLLM scheduler to hold the historical KV cache fixed and immediately re-queue the same block for its next refinement pass, with no changes to the core scheduling engine required.
The framework also dynamically manages two additional mechanisms:
- Self-Conditioning: the model feeds continuous probability distributions from the previous denoising step back into the network, stabilizing the parallel refinement trajectory.
- Dynamic Attention Masks: causal text requests maintain a standard left-only attention window; diffusion blocks instantly switch to a symmetric sliding window that peers both forward and backward across the canvas.
Performance Trade-offs and Benchmarks
DiffusionGemma is a highly specialized architectural alternative, not an absolute replacement for frontier autoregressive models. Parallel block generation delivers exceptional speed, but requires accepting a clear trade-off in zero-shot reasoning capability.

The core trade-off: DiffusionGemma dominates on speed but trails on zero-shot complex reasoning, especially advanced mathematics.
| Benchmark | Focus | DiffusionGemma 26B | Gemma 4 26B (AR) |
|---|---|---|---|
| MMLU Pro | Complex multilingual Q&A | 77.6% | 82.6% |
| MMMLU | Multimodal contextual Q&A | 81.5% | 86.3% |
| AIME 2026 (no tools) | Advanced mathematical logic | 69.1% | 88.3% |
| LiveCodeBench v6 | Real-world software engineering | 69.1% | 77.1% |
| BigBench Extra Hard | Intricate linguistic logic | 47.6% | 64.8% |
The most striking regression is the 19.2% gap on AIME 2026. The reason is architectural: autoregressive transformers build logical paths step-by-step, with each token strictly conditioned on a finalized history, enabling tight sequential deduction chains. Diffusion models evaluate the entire block simultaneously. This is highly effective for enforcing global syntax layouts, but prone to losing the thread of sequential mathematical reasoning in zero-shot settings.
Zero-shot benchmarks do not tell the full story. Google demonstrated this by fine-tuning DiffusionGemma on Sudoku puzzles, a strict multivariable constraint problem that traditional LLMs consistently fail because they cannot plan for future cells while filling the current one.
- Zero-shot baseline: 0% success rate, timing out at the 48-step ceiling.
- After targeted SFT: 80% success rate, solved in just 12 parallel steps.
This proves that while generic zero-shot logic benchmarks are lower, diffusion language models possess exceptional spatial and structural planning capabilities that can be unlocked via targeted fine-tuning.
Why Developers Should Care
For software engineers and AI systems architects, a compute-bound model completely rewrites how local applications are designed. Three use cases stand out.
Tools like Cursor and Windsurf rely heavily on code infilling. Traditional models ingest the top half of a file, guess the middle, and attempt to align with the bottom half using only left-to-right context, leading to duplicated brackets and broken indentations. DiffusionGemma sees the prefix and suffix simultaneously and refines the blank block until the syntax fits the surrounding context perfectly. Combined with 700+ tokens/sec local generation, real-time code infilling becomes nearly instantaneous.
Autonomous agents spend substantial compute on routing tasks via structured JSON payloads. Autoregressive models are prone to truncating trailing curly braces if context limits are reached, breaking JSON parsers and stalling the agentic loop. DiffusionGemma enforces structural parameters across the entire canvas simultaneously, ensuring that schemas open and close correctly. Its ultra-low latency makes it highly effective as a local intent router, parsing inputs, firing structured tool calls, and orchestrating downstream models in milliseconds.
Fast local LLM inference historically required hardware with massive memory buses. Because DiffusionGemma is compute-bound, its performance scales with raw GPU TFLOPS rather than memory bandwidth, aligning perfectly with the architecture of consumer gaming GPUs like the RTX 4090 and 5090. This creates a massive advantage for completely offline, high-privacy applications: on-device call screeners, local document parsers, offline educational tools, and similar use cases can now process sensitive data rapidly without cloud-based APIs.
The Bigger Picture: Is This the Future of AI Architecture?
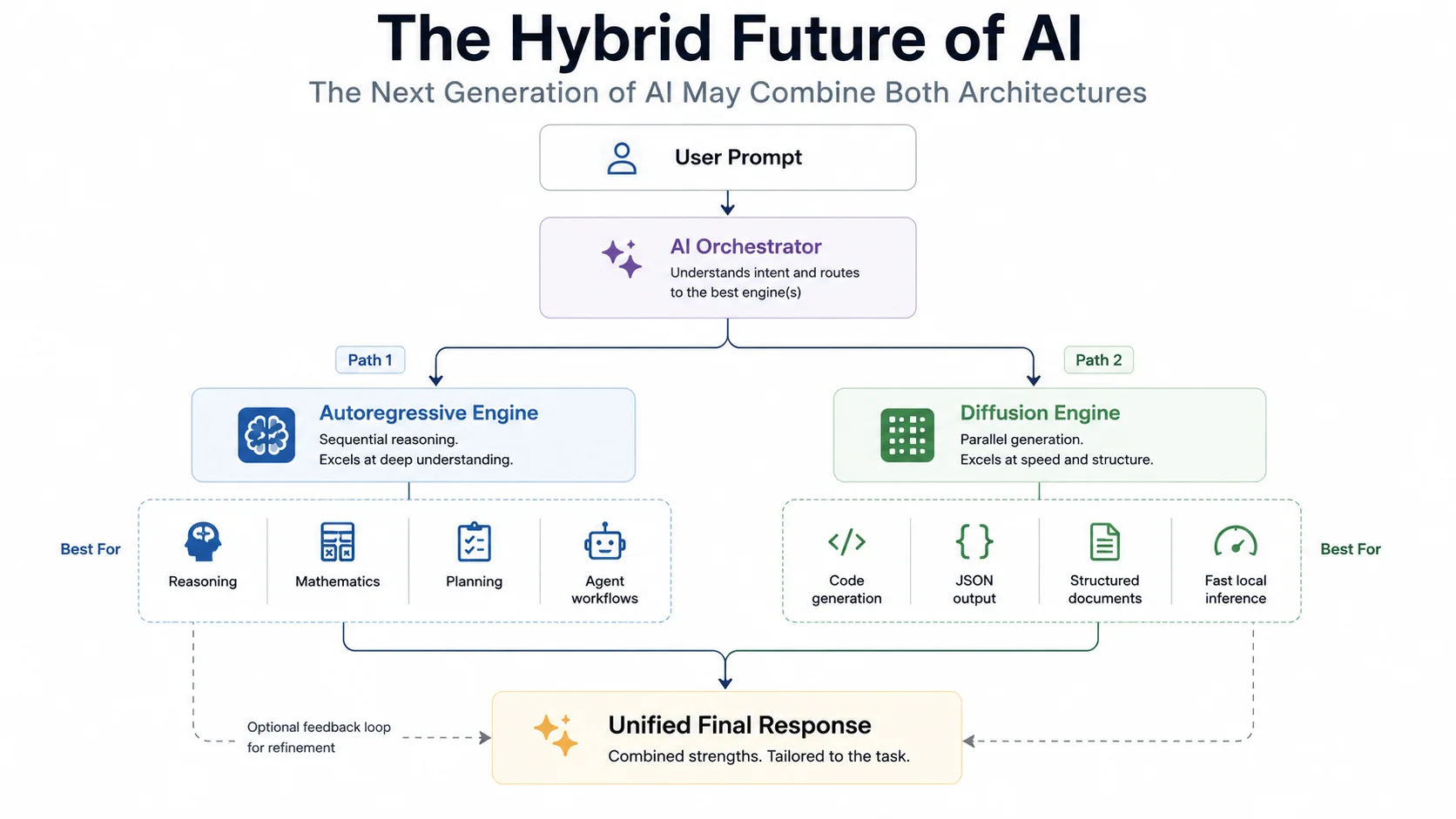
The next decade of inference: hybrid architectures routing between sequential reasoning and parallel diffusion blocks depending on task type.
Will discrete text diffusion entirely replace the autoregressive transformer? Over the next five years, the industry is more likely to move toward architectural hybridization. Pure diffusion models excel at spatial arrangement, structural formatting, and global syntax, but lag in zero-shot sequential mathematical reasoning. Google's Block Autoregressive approach, combining causal encoding blocks with parallel diffusion canvases, is an early production example of this direction.
Future inference engines will likely route tasks dynamically within a unified framework: employing sequential autoregressive generation for complex chain-of-thought logic, then switching to parallel diffusion blocks to write code fragments or output massive structured JSON payloads, with no memory-bandwidth bottleneck in sight.
- The Memory Wall is real. Autoregressive models reload tens of gigabytes of weights per token, leaving GPU compute idle up to 90% of the time on single-user local inference.
- Discrete diffusion shifts the bottleneck. By generating 256 tokens in parallel, DiffusionGemma loads weights once per pass and applies them across the full canvas, making inference compute-bound instead of memory-bound.
- Bidirectional attention eliminates the reversal curse. Seeing the full context simultaneously fixes the directional knowledge asymmetry inherent to causal models.
- The speed-reasoning trade-off is real. Zero-shot math and logic scores drop measurably, but targeted fine-tuning can unlock spatial and structural reasoning that autoregressive models cannot match.
- Best deployment targets: code infilling, structured JSON generation, offline privacy-critical tools, and high-throughput local applications on consumer GPUs.
Common Misconceptions
It is a fundamentally different architecture. Autoregressive models predict one token at a time conditioned on a finalized left-to-right history. DiffusionGemma initializes a full block of noise and iteratively denoises all tokens in parallel using bidirectional attention. The speed gain is not from optimization. It comes from an entirely different computational paradigm.
Speed and reasoning quality measure different axes of capability. DiffusionGemma generates text extremely fast but scores measurably lower on complex zero-shot mathematical reasoning. For tasks like solving AIME problems or long chain-of-thought derivations, a slower autoregressive model will produce more accurate results. Choose the architecture that matches your workload, not just the one with the highest throughput number.
The canvas is a processing unit, not an output limit. DiffusionGemma generates long text by producing multiple 256-token canvases sequentially, committing each completed block into the KV cache before starting the next. The architecture supports extended generation; the canvas boundary simply defines the granularity of parallel refinement.
Frequently Asked Questions
No. DiffusionGemma is an experimental architecture optimized for low-latency, highly structured applications. It lacks the raw zero-shot mathematical and logical reasoning capacity of major frontier autoregressive models, scoring notably lower on advanced math benchmarks like AIME 2026. Think of it as a specialized co-processor for speed-critical structured tasks, not a general-purpose frontier replacement.
When quantized to FP8 or NVIDIA's 4-bit floating-point format (NVFP4), DiffusionGemma fits within 18GB to 24GB of VRAM, making it fully compatible with consumer hardware like the RTX 4090 and 5090. The full-precision 26B model would require significantly more; quantization is essentially required for practical local deployment.
The reversal curse is a structural limitation where an autoregressive model trained on an asymmetric fact, for example "Person A wrote Book B," and struggles to infer the reverse relationship ("Book B was written by Person A") because causal attention masks prevent the network from looking forward during training. DiffusionGemma avoids this entirely through bidirectional attention, which sees the full canvas context simultaneously from the first denoising step.
It is currently suboptimal for deep RAG. DiffusionGemma scores 32.0% on the MRCR v2 128k benchmark, compared to standard Gemma 4's 44.1%. Processing text in iterative 256-token blocks makes it harder to pull isolated facts from massive contextual histories. For long-context retrieval pipelines, a standard autoregressive model with a large KV cache is the better choice.
Yes. DiffusionGemma supports Parameter-Efficient Fine-Tuning via LoRA and QLoRA. Toolkits like Unsloth provide optimized training paths that reduce VRAM consumption by up to 70%, allowing adaptation on standard local rigs. Google's Sudoku case study demonstrates how targeted SFT can unlock domain-specific capabilities, such as spatial constraint solving, that zero-shot benchmarks would never reveal.