Weight-Only Quantization
Weight-only quantization (e.g., W4A16 or INT8 weights) compresses the model's static weights into low-precision formats while keeping dynamic runtime
Source: mortalapps.com- Weight-only quantization (e.g., W4A16 or INT8 weights) compresses the model's static weights into low-precision formats while keeping dynamic runtime activations in high-precision FP16 or BF16.
- The core purpose is to strictly maximize inference throughput by alleviating severe memory bandwidth bottlenecks.
- The primary optimization is utilizing fast, fused dequantization kernels that dynamically upcast the weights directly inside the GPU registers immediately prior to computation.
- The key engineering insight is that weight-only quantization accelerates memory-bound workloads (like batch-size-1 decoding) but provides zero benefit to compute-bound workloads (like massive prompt prefilling).
Why This Matters
Inference generation on massive language models operates under two entirely different physical constraints depending on the phase. During the autoregressive decoding phase (generating tokens one by one), the GPU compute units sit idle for the vast majority of the time, waiting for the massive matrix of weights to travel from High Bandwidth Memory (HBM) to the streaming multiprocessor (SM) SRAM. Compressing the weights down to 4-bit (W4A16) effectively quadruples the memory bus capacity, directly solving the primary hardware limitation and enabling real-time generation on edge devices and single-GPU servers that otherwise could not even load the model.
Core Intuition
Imagine a factory (the GPU compute cores) receiving raw materials (the weights) from a warehouse via a single highway (the memory bus). In decoding, the factory builds products so fast that the highway cannot deliver materials quickly enough. To solve this, we crush the materials into tiny cubes (4-bit quantization) so four times as many fit on a single truck. When the truck arrives at the factory floor, a dedicated machine instantly expands the cubes back to full size (in-register dequantization) right before they are thrown into the assembly line. Because the expansion happens on the factory floor, the highway traffic is solved, and the factory operates at full capacity.
Technical Deep Dive
Weight-only quantization algorithms, such as those utilized by AWQ or GPTQ, generally employ group-wise quantization. Rather than scaling an entire tensor globally, a row of weights is segmented into localized groups (typically  ). Each distinct group is assigned a high-precision FP16 scale and an INT4 zero-point. During inference, a highly optimized kernel is dispatched. It receives an FP16 activation matrix, a packed INT32 weight matrix (where one 32-bit integer holds eight 4-bit weights), and the corresponding scale parameters. The kernel fetches the packed data and utilizes parallelized bitwise shift operations to extract the 4-bit sub-values, applying the dequantization formula mathematically in the registers:
). Each distinct group is assigned a high-precision FP16 scale and an INT4 zero-point. During inference, a highly optimized kernel is dispatched. It receives an FP16 activation matrix, a packed INT32 weight matrix (where one 32-bit integer holds eight 4-bit weights), and the corresponding scale parameters. The kernel fetches the packed data and utilizes parallelized bitwise shift operations to extract the 4-bit sub-values, applying the dequantization formula mathematically in the registers:
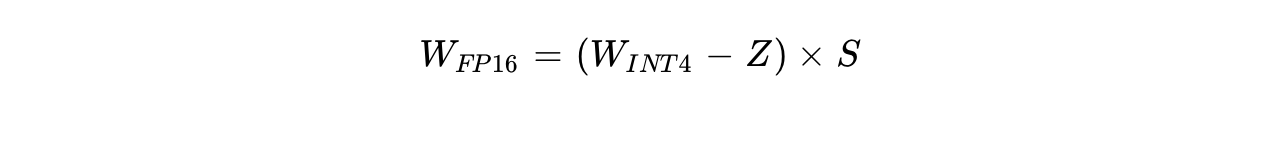
This allows the FP16 weight and the FP16 activation to execute cleanly through the standard Tensor Cores.
Key Takeaways
Internals / Execution Flow
Executing W4A16 mathematically involves the following GPU lifecycle:
Memory Fetch: Load the packed INT32 chunks alongside their FP16 scales from HBM to shared memory.
Register Unpacking: Using SIMD instructions (like CUDA PTX or ARM NEON 128-bit), apply bitwise AND masks and shift operators to unpack the tightly grouped integers.
Dequantization: Apply the scale  and shift
and shift  directly inside the fast FP32 registers.
directly inside the fast FP32 registers.
GEMM Execution: Feed the newly inflated FP16 weight and original FP16 activation into the Tensor Core dot-product engine.
Epilogue: Write the result back to global memory.