Gemini-SQL2 Architecture Review: Enterprise Implications for Autonomous Analytics
Google's text-to-SQL model just crossed 80% execution accuracy on BIRD. The question is no longer whether AI can write SQL. It is what infrastructure is required to let it do so safely at scale.
Every enterprise data platform eventually collides with the same operational reality: there is an insurmountable gap between the speed of business questions and the capacity of data engineering teams. Relational data architectures remain the undisputed bedrock of enterprise intelligence, yet extracting actionable insight from modern transactional and analytical data systems involves an ongoing structural bottleneck.
While business strategies change by the hour, data accessibility remains constrained by a dependency on technical specialists. The traditional query pipeline looks like this:
Data engineers and DBAs spend a disproportionate share of their cycles translating business requirements into complex SQL. Over the last decade, organizations attempted to solve this with self-service analytics and dashboard-heavy BI tools. But self-service BI only works for pre-aggregated, anticipated questions. The moment an executive asks something that falls outside a pre-built dashboard, the user is sent back into the data engineering ticket queue.
The integration of Large Language Models fundamentally altered this trajectory. Yet early enterprise AI analytics deployments revealed severe architectural flaws. Massive foundational models possessed deep familiarity with standard SQL keywords but failed consistently when deployed against proprietary enterprise schemas, hallucinating columns and misinterpreting specialized business logic.
This technical report evaluates Gemini-SQL2, assessing its core architectural design, benchmark performance metrics, and the enterprise infrastructure required to transform probabilistic language generation into a safe, reliable, and production-grade enterprise data agent.
- 80.04% Execution Accuracy: Gemini-SQL2 achieves state-of-the-art on the BIRD Single-Model Leaderboard, narrowing the gap to human baseline (92.96%) to just 12.92 points.
- The Semantic Bottleneck: The primary enterprise constraint has shifted from generating SQL code to maintaining rigorous semantic layers, context sets, and metadata quality.
- Context Engineering is Mandatory: High accuracy in production requires continuous maintenance of structured JSON Context Sets. Zero-shot prompting is insufficient.
- Deterministic Security is Required: Open-ended data copilots are highly susceptible to advanced prompt injection. Security must be decoupled from the LLM via database-native Parameterized Secure Views.
- Infrastructure, Not an App: Capabilities like Gemini-SQL2 should be treated as a core infrastructure update governed by the Model Context Protocol, not an independent AI software layer.
- The Evolution of Text-to-SQL Benchmarks
- What Is Gemini-SQL2?
- Why Execution Accuracy Matters More Than SQL Syntax
- Beyond SQL Generation: Enterprise Data Agents
- Reference Architecture for Enterprise Conversational Analytics
- The Real Bottleneck Shift
- Enterprise Analytics Maturity Model
- Implications for Business Intelligence Platforms
The Evolution of Text-to-SQL Benchmarks
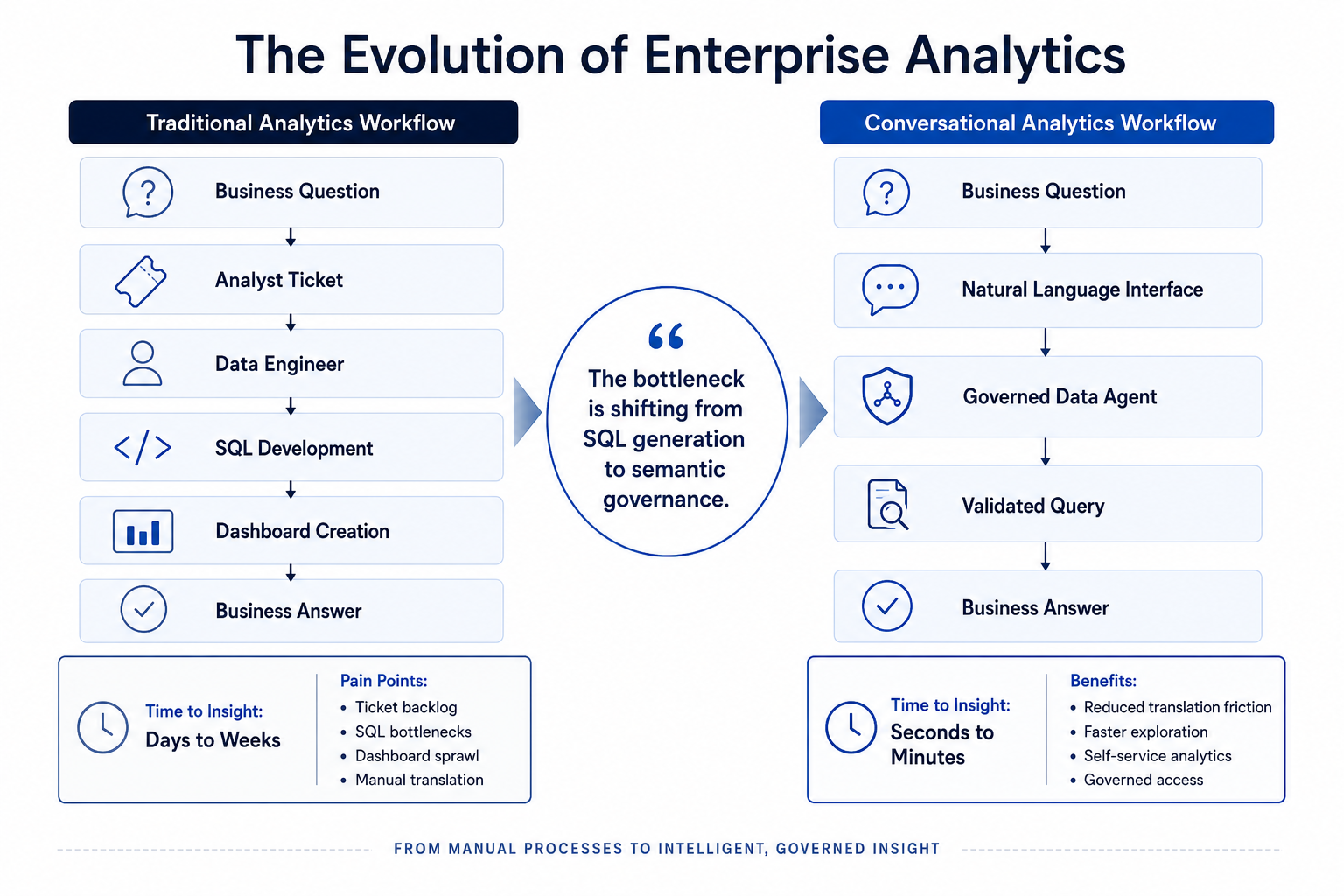
The operational bottleneck is shifting from SQL generation to semantic governance. Time-to-insight drops from days to seconds when the architecture is right.
The Limitations of Spider and Exact-Match Evaluation
For several years, the cross-domain standard for text-to-SQL systems was the Spider dataset. Spider evaluated models primarily on Exact Match (EM) accuracy: a direct, string-to-string comparison between the model-generated SQL syntax and a gold-standard reference query written by human annotators.
While Spider forced systems to improve general syntactic generation capabilities, EM testing introduced major structural blind spots for enterprise teams:
- Syntactic Bias: Exact Match penalizes a model for writing structurally valid, computationally efficient SQL if the selected join paths diverge textually from the human reference query.
- Schema Simplicity: Spider databases rely on clean, normalized, and highly simplified schemas that do not reflect the legacy complexity of authentic corporate data environments.
- No Data Grounding: EM metrics completely ignore physical database contents. A model can generate a query that looks flawless on paper but returns zero rows in practice because it misinterprets the actual values stored inside the tables.
The Shift to BIRD and Execution Accuracy
The introduction of the BIg Bench for LaRge-scale Database Grounded Text-to-SQL Evaluation (BIRD) redefined the testing landscape by prioritizing Execution Accuracy (EX) over rigid syntax matching. Under BIRD, a generated query is physically compiled and executed against a live database. The resulting dataset is compared directly to the gold standard output. If the result sets match identically, the model receives a passing mark, regardless of the structural path taken by the query planner.
BIRD's internal design explicitly replicates authentic enterprise parameters:
- Scale: 12,751 distinct question-SQL pairs across 95 heavy databases, accumulating 33.4 GB of data across 37 unique industry segments.
- Complexity: Production schemas in BIRD feature dirty data values, undocumented columns, extensive primary/foreign key join relationships, and multi-layered nested subqueries.
- Performance Metrics: BIRD also evaluates the Valid Execution Score (VES) and Relative Valid Execution Score (R-VES), penalizing queries that yield correct data but require unoptimized, high-latency operations.
Execution accuracy is a risk-management metric, not an AI metric. For years, AI platforms sold "SQL generation" as the solution, assuming the database would sort out the rest. Execution-based benchmarks proved that syntactic fluency without semantic data grounding is a severe operational liability.
What Is Gemini-SQL2?
Gemini-SQL2 represents a targeted optimization of Google's foundational AI models specifically engineered for advanced relational data interactions. Rather than deploying an expensive, multi-stage software scaffolding wrapper, Gemini-SQL2 is evaluated within the rigid constraints of the BIRD Single Trained Model Track, which completely prohibits multi-agent voting networks or external retrieval-augmented generation (RAG) loops during evaluation.
Benchmark Performance
Within this track, Gemini-SQL2 achieved an Execution Accuracy of 80.04% on the official BIRD leaderboard. The human baseline, established by a pool of professional data engineers and database graduate students, sits at 92.96%. The prior generation framework, Gemini-SQL (which relied on Multitask Supervised Fine-Tuning over Gemini 2.5 Pro), capped at 76.13%. By passing the 80% mark, Gemini-SQL2 narrows the variance to 12.92 percentage points, moving into a performance tier where generated code is natively execution-ready.
BIRD Single Trained Model Track: Execution Accuracy (%)
| System / Model | Sponsoring Entity | BIRD EX Accuracy | Context |
|---|---|---|---|
| Human Performance Baseline | Research Cohort | 92.96% | Established benchmark baseline |
| Gemini-SQL2 | Google Research & Cloud | 80.04% | Current state-of-the-art record |
| Q-SQL (30B-3B-MoE) | AWS Quick Science | 76.47% | Prior cloud record leader |
| Databricks RLVR 32B | Databricks Mosaic | 75.70% | Reinforcement learning optimized |
| SiriusAI-Text2SQL-Agent | Tencent AI Lab | 75.35% | Production-tuned agent core |
| Arctic-Text2SQL-R1-32B | Snowflake Engineering | 73.90% | Open weights baseline champion |
| GPT-5.5-xhigh | OpenAI | 72.55% | General-purpose frontier model |
Why Execution Accuracy Matters More Than SQL Syntax
For an enterprise platform team, syntax validation provides a false sense of security. A text-to-SQL system that produces clean, standard SQL that compiles without a syntax error can still cause significant operational damage if it lacks semantic alignment with the underlying data distribution.
The Illusion of Syntactic Safety
Consider an enterprise resource planning (ERP) database tracking global transactions. A business stakeholder asks: "What is the total margin generated by electronic component sales across the EMEA region for the last quarter?"
An ungrounded LLM may produce the following structurally flawless query:
This statement compiles and runs without errors. However, in this production enterprise schema:
- Implicit Deletions: The transactions table contains a soft-delete flag (
is_canceled). Failing to appendAND t.is_canceled = FALSEcauses the query to over-report margin by millions of dollars. - Entity Ambiguity: The string value
'EMEA'is split across sub-billing codes in the regional mapping directory.t.region_code = 'EMEA'matches exactly zero records because the actual data stores records as'EMEA_NORTH'and'EMEA_SOUTH'.
The SynSQL Disruption
The critical danger of relying entirely on static benchmarks was demonstrated using SynSQL, a synthetic data generation platform designed to expose modeling gaps. Researchers held the base schema structure of tested databases completely static but dynamically altered the underlying statistical data distributions and record content. When top-performing text-to-SQL architectures were re-evaluated against these mutated environments, performance metrics degraded abruptly:
This degradation indicates that many top models are not truly comprehending the relationship between human language and relational structures. Instead, they are overfitting to static data conditions and memorizing benchmark artifacts. Enterprise leaders cannot assume that a model which understands their schema will automatically understand their data.
Context quality is becoming a new form of data quality. You can have perfectly clean tabular data, but if the context connecting natural language to that data is flawed or missing, the resulting analytics will be entirely inaccurate.
Beyond SQL Generation: Enterprise Data Agents
Google QueryData: The Grounding Layer
To operationalize architectures like Gemini-SQL2, Google Cloud launched QueryData: a specialized generative tool that translates natural language into queries for AlloyDB, Cloud SQL, and Google Spanner, designed for high-reliability, production-oriented execution.
QueryData addresses the accuracy challenge via Context Sets. A foundational LLM cannot inherently know that in a specific enterprise schema, an order status of "1" means "shipped" and "2" means "returned". A Context Set acts as the specialized, injected knowledge fueling the data agent. It consists of JSON-formatted descriptions and explicit instructions unique to that specific database deployment.
A production Context Set contains three core architectural elements:
| Component | What It Does | Example |
|---|---|---|
| Templates | Maps specific natural language intents to parameterized SQL query blueprints | "Show Q3 margin" maps to a pre-validated SUM query with date parameters |
| Facets | Isolated, reusable SQL blocks mapped to explicit business concepts | "Average salary between 6000 and 10000" maps to employee."A11" BETWEEN 6000 AND 10000 |
| Value Searches | Hard links binding colloquial terms to exact column-level data distributions | "EMEA" maps to values EMEA_NORTH and EMEA_SOUTH in region_code |
When a query is fundamentally ambiguous, QueryData operates under a fail-safe paradigm: it halts execution to return a clarifying question to the user rather than hallucinating an incorrect table scan.
Context engineering replaces prompt engineering in the enterprise. Prompt engineering is probabilistic and unreliable. Context Sets are deterministic and version-controlled.
The Security Challenge: Empirical Proof of LLM Exploitation
Deploying a read-write data copilot introduces uniquely severe cybersecurity vulnerabilities. Relying on purely probabilistic LLMs to govern access control is fundamentally flawed and highly susceptible to prompt injection.
A landmark 2026 cybersecurity study conducted 400 autonomous penetration testing runs against honeypots. The models deployed 98 unique, sophisticated attack strategies. Gemini 2.5 Flash-Lite achieved full server exploitation in 85 out of 100 runs. Claude Sonnet 4 achieved full exploitation in 61 runs, with cross-service credential reuse appearing frequently. This conclusively demonstrates that LLMs are inherently capable of executing multi-stage cyber attacks, including advanced SQL injection.
The Solution: Parameterized Secure Views (PSVs)
To neutralize these threats, database architectures must enforce rigid security below the application layer via Parameterized Secure Views (PSVs). PSVs lock down data access by ensuring mathematically that the application user can only view authorized rows, entirely independent of the SQL syntax generated by the LLM.
If an organization relies purely on application-layer logic to prevent a user from seeing another user's data, the architecture will inevitably fail a compliance audit. Parameterized Secure Views are not optional for production enterprise deployments.
Reference Architecture for Enterprise Conversational Analytics
To orchestrate the transition from raw language generation to secure, deterministic enterprise execution, organizations must adopt a hardened reference architecture that physically separates generation, governance, and execution into three distinct zones.
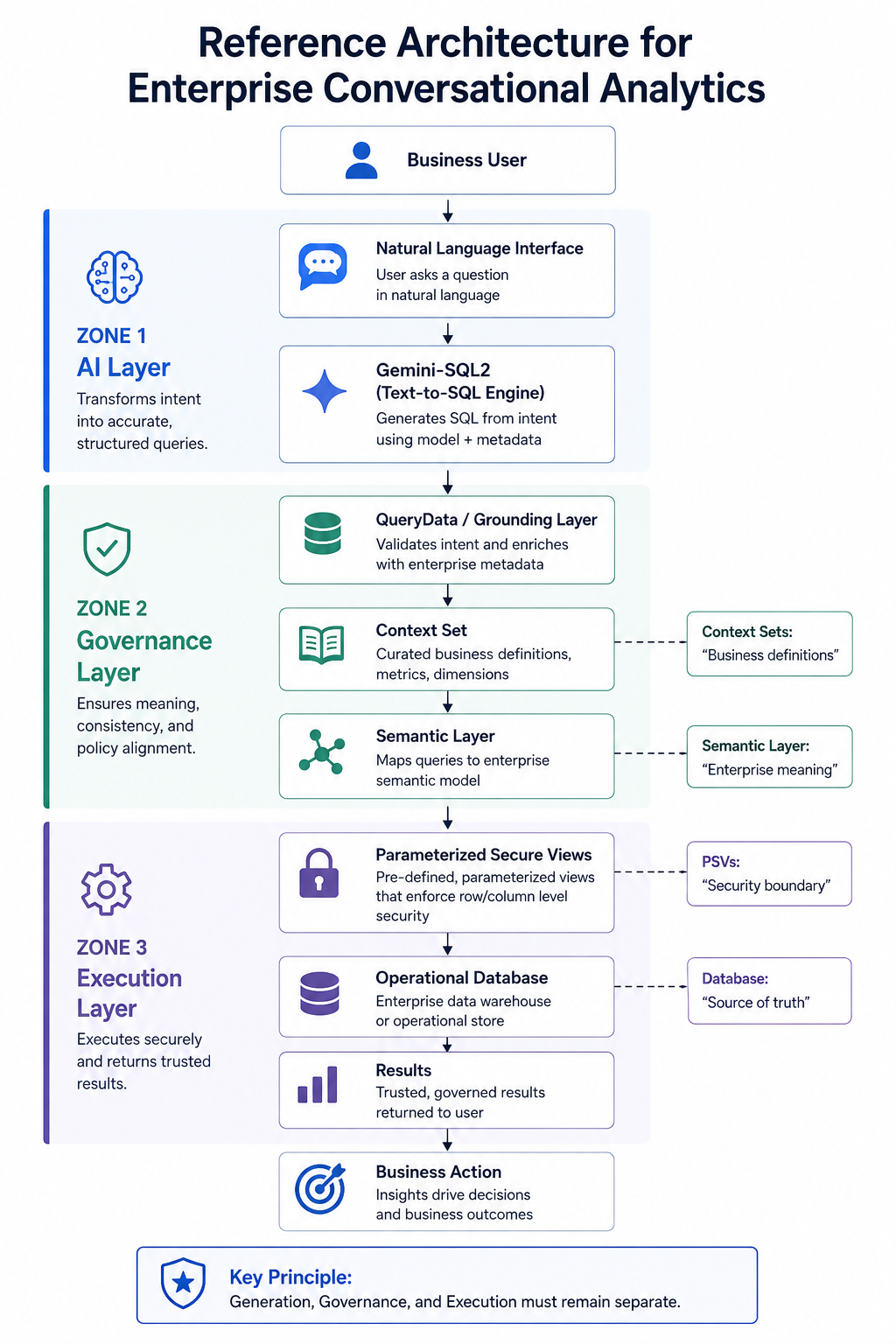
The three-zone enterprise architecture for conversational analytics. Generation, Governance, and Execution must remain separate.
| Architectural Layer | Status | Why |
|---|---|---|
| LLM Engine (e.g., Gemini-SQL2) | Mandatory | Parses unstructured natural language requests into programmatic intent |
| Context Set | Mandatory | Prevents hallucinations by grounding the model in approved business logic. Operating without this layer ensures rapid semantic rot. |
| Semantic Layer (LookML, dbt) | Recommended | Acts as a centralized repository for business metrics. Generating Context Sets dynamically from a governed Semantic Layer ensures AI definitions match traditional BI dashboards. |
| Parameterized Secure Views | Mandatory | The un-bypassable database engine constraint enforcing row-level security independently of LLM output. |
This architecture physically separates generation (the LLM) from execution and authorization (the database engine). This decoupled design is the only way to deploy conversational analytics safely in a regulated enterprise. Executive leaders must ensure platform budgets adequately cover the grounding and security layers, not just the model APIs.
The Real Bottleneck Shift
As models cross the 80% execution accuracy threshold, the primary constraint on enterprise AI analytics is no longer generating the code. The operational bottleneck has shifted decisively from syntax generation to semantic orchestration.
Data warehouses store data. Semantic layers store meaning. AI systems require both.
If an enterprise has invested millions migrating to a cloud warehouse but failed to map its business rules into a universal semantic layer, it effectively has an infinitely scalable repository of unstructured ambiguity. A data warehouse without a semantic layer relies entirely on human tribal knowledge to extract value. An AI model possesses no tribal knowledge.
Historically, data engineers spent their days translating a business user's request into a complex JOIN statement. Today, the LLM can generate the JOIN statement in milliseconds. However, if the business user and the database have conflicting definitions of "net recurring revenue," the LLM will still fail.
The new bottleneck encompasses three specific areas:
- Context Engineering: Building the JSON structures that tell the LLM which tables represent which business concepts.
- Metadata Quality: Ensuring table schemas, column names, and data dictionaries are accurately documented. If a column is vaguely named
col_009_b, no AI model can query it accurately without explicit manual mapping. - Data Quality and Governance: AI models have zero tolerance for tribal knowledge. If the only way to accurately query the inventory table is to remember to filter out records where
store_id = 9999(a legacy test environment), the AI will fail unless this rule is hardcoded into the semantic layer.
The shift is profound. Rolling out a natural language data interface is not primarily an AI project. It is a master data management and governance project.
Metadata may become more valuable than model scale. A 7-billion parameter model operating on perfectly structured, heavily mapped enterprise metadata will consistently outperform a 1-trillion parameter model operating in an undocumented data swamp.
Enterprise Analytics Maturity Model
To evaluate where an organization stands in its adoption of text-to-SQL frameworks, IT leadership should benchmark against the following five-level maturity model.
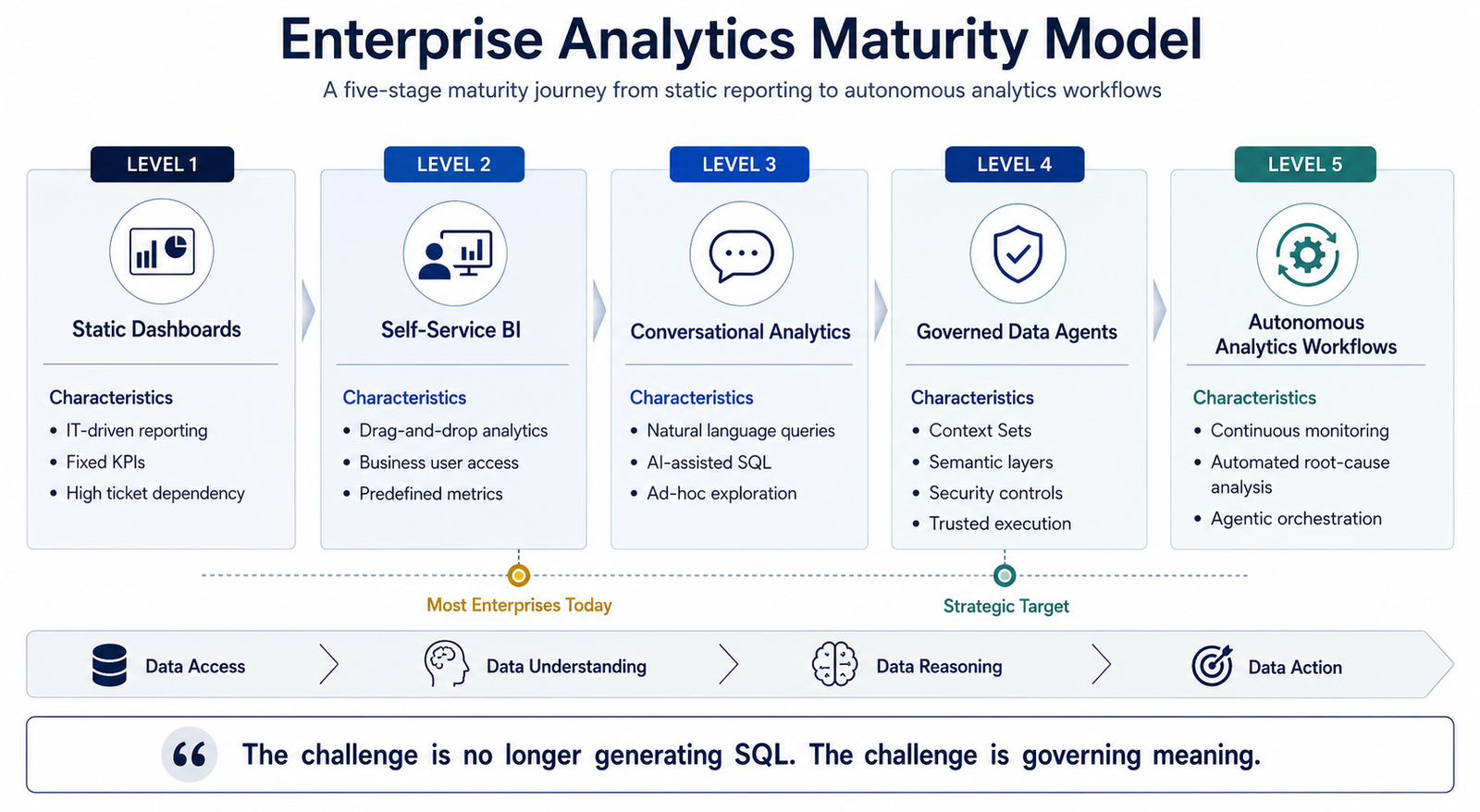
Most enterprises today operate at Level 2. Governed Data Agents (Level 4) represent the strategic target for AI-driven analytics.
Implications for Business Intelligence Platforms
The integration of robust text-to-SQL agents at the database level fundamentally disrupts the traditional Business Intelligence software landscape. If a business user can ask a governed agent a question via Slack or Teams and receive a validated, chart-ready dataset, the necessity of the standard static dashboard is called into question.
| BI Platform Category | Example Vendors | AI Impact | Strategic Outcome |
|---|---|---|---|
| Traditional Dashboarding | Tableau, Power BI | Negative | Dashboards become reserved exclusively for executive KPIs and highly regulated statutory reporting. Ad-hoc dashboard creation declines sharply. |
| Semantic-Led Platforms | Looker (LookML), Cube | Highly Positive | The semantic layer becomes the most critical asset in the enterprise. LookML provides the perfect structured input to feed tools like QueryData. |
| Cloud-Native / Spreadsheet | Sigma | Positive | Spreadsheets remain universally understood. Integrating text-to-SQL within cloud-native spreadsheet interfaces allows massive ad-hoc flexibility over cloud warehouses. |
| MCP-Native / Agentic Platforms | Emerging category | Highly Positive | Platforms built natively around the Model Context Protocol (MCP) become the connective tissue between LLM engines, semantic layers, and operational databases. |
Analytics bottlenecks are becoming organizational rather than technical. The technology to translate English to SQL exists today. The reason enterprises still struggle with reporting is that their internal definitions of success remain dangerously fragmented across teams, systems, and tribal knowledge.
The Challenge is No Longer Generating SQL
Gemini-SQL2 represents a genuine inflection point in enterprise data accessibility. By achieving 80.04% execution accuracy under the most rigorous single-model constraints on the BIRD leaderboard, it demonstrates that natural language interfaces have crossed from experimental prototype to production-viable capability.
But the model itself is only the entry point. The architecture surrounding it determines whether an enterprise benefits or suffers. Organizations that invest in context engineering, semantic layer governance, and deterministic security controls will unlock the full value of this capability. Those that deploy the model API alone will encounter the same hallucinations, data errors, and security vulnerabilities that have plagued early enterprise AI deployments.
The challenge is no longer generating SQL. The challenge is governing meaning.