Roofline Modeling and Performance Bounds
Represents a visual and mathematical model mapping application execution performance strictly against physical hardware limitations.
Source: mortalapps.com- Represents a visual and mathematical model mapping application execution performance strictly against physical hardware limitations.
- The core purpose is identifying the absolute theoretical performance ceiling of a given workload to evaluate optimization maturity.
- The primary optimization idea focuses on shifting arithmetic intensity to maximize compute unit utilization before hitting memory limits.
- The most important engineering insight is that throwing more compute (Tensor Cores) at a memory-bound algorithm yields absolutely zero performance gains; the algorithm itself must be restructured.
Why This Matters
Without a mathematically bounded model, performance engineering is entirely aimless. Roofline models dictate to engineers exactly when to stop optimizing. If an AI inference system is currently operating at 95% of the theoretical speed-of-light for memory bandwidth, further low-level code tweaking is wasted engineering time. Understanding performance bounds dictates major cluster architecture purchasing decisions, accurately determining whether a specific model architecture demands High Bandwidth Memory (HBM3) or denser arithmetic Tensor Cores to scale effectively.
Core Intuition
The Roofline model plots Performance (measured in FLOPs per second) on the Y-axis against Arithmetic Intensity (measured in FLOPs per Byte) on the X-axis. The resulting plot resembles a roof: a sloped line rising from the origin representing the memory bandwidth limit, intersecting with a flat horizontal line representing the peak theoretical compute limit. A workload's position as a coordinate point on this graph instantly defines its true bottleneck. If the point lies directly under the sloped line, data cannot be fed fast enough. If it lies under the flat line, the mathematical units are fully saturated.
Technical Deep Dive
Calculating theoretical points requires precise hardware specifications combined with empirical profiling metrics. The empirical derivation for Arithmetic Intensity ( ) is defined as Total FLOPs divided by Total DRAM Bytes. Nsight Compute systematically extracts these parameters. FLOPs are heavily dependent on precision formats. As observed in profiling metrics, Single Precision (SP) FLOPs are calculated by aggregating opcodes, explicitly sm__sass_thread_inst_executed_op_fadd_pred_on.sum plus twice the ffma count and the fmul count. Tensor core instructions multiply the executed pipeline count by a factor of 512.7 Bytes transferred are retrieved via the dram__bytes.sum metric.
) is defined as Total FLOPs divided by Total DRAM Bytes. Nsight Compute systematically extracts these parameters. FLOPs are heavily dependent on precision formats. As observed in profiling metrics, Single Precision (SP) FLOPs are calculated by aggregating opcodes, explicitly sm__sass_thread_inst_executed_op_fadd_pred_on.sum plus twice the ffma count and the fmul count. Tensor core instructions multiply the executed pipeline count by a factor of 512.7 Bytes transferred are retrieved via the dram__bytes.sum metric.
| Roofline Region | Equation Dynamics |
|---|---|
| Implication | Memory-Bound (Sloped) |
 | Performance scales linearly with algorithmic intensity improvements. |
| Compute-Bound (Flat) | 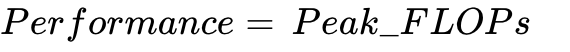 |
| Performance is capped by silicon capability; intensity improvements yield nothing. | Ridge Point |
| Intersection of Bandwidth and Compute | The optimal operating point for maximum hardware extraction. |
Key Takeaways
Real-World Usage
In LLM architecture design, Roofline models actively dictate primitive operator choices. Standard self-attention mechanisms are notoriously memory-bound because they must load massive  matrices to perform relatively simple mathematical reductions. Innovations like FlashAttention restructure the algorithm entirely using tiling methodologies to keep data resident in extremely fast SRAM. This effectively moves the workload's arithmetic intensity to the right along the X-axis, pushing it aggressively up the sloped roof toward the ultimate compute boundary.
matrices to perform relatively simple mathematical reductions. Innovations like FlashAttention restructure the algorithm entirely using tiling methodologies to keep data resident in extremely fast SRAM. This effectively moves the workload's arithmetic intensity to the right along the X-axis, pushing it aggressively up the sloped roof toward the ultimate compute boundary.