Context Parallelism
Represents an architectural evolution of Sequence Parallelism designed specifically to accommodate extreme (million-token) context regimes.
Source: mortalapps.com- Represents an architectural evolution of Sequence Parallelism designed specifically to accommodate extreme (million-token) context regimes.
- Usually implemented natively via Ring Attention or Blockwise self-attention mathematical primitives.
- Divides the massive
 attention matrix computation geographically across the GPU cluster to bypass memory constraints entirely.
attention matrix computation geographically across the GPU cluster to bypass memory constraints entirely. - Integrated deeply with enterprise frameworks like NVIDIA NeMo to eradicate computationally expensive activation recomputation overheads.
Why This Matters
As target sequence lengths cross the 1-million token threshold (exemplified by models like Gemini 1.5), the self-attention mechanism becomes the absolute, insurmountable computational and memory bottleneck. Context Parallelism (CP) allows the sequence dimension processing capability to scale linearly with the addition of physical GPUs. Without robust CP infrastructure, training multi-modal or extreme-context LLMs remains mathematically impossible due to memory exhaustion, even when paired with the most aggressive activation checkpointing methodologies.
Core Intuition
Unlike Sequence Parallelism (Ulysses), which violently shuffles tokens across the network to compute full attention locally on a subset of heads, Context Parallelism (via Ring architectures) keeps the Query blocks stationary on their respective GPUs. Instead, it systematically rotates the Key and Value blocks around a physical network ring. Each GPU computes a highly specific geometric tile of the massive attention matrix. Over time, as the K/V blocks complete their circuit around the cluster, the full attention output is aggregated incrementally without ever materializing the full matrix in memory.
Technical Deep Dive
Context Parallelism heavily leverages blockwise causal masking. In a standard causal transformer, Token 100 is mathematically prohibited from attending to Token 200. When geometrically distributing sequence blocks across 4 GPUs (e.g., GPU 1 processes 0-25k, GPU 2 processes 25k-50k), CP systems optimize network communication by explicitly dropping and bypassing K/V blocks that fall entirely within the causal mask of the target GPU.
Hierarchical Context Parallelism (HCP) allows engineers to define heterogeneous CP strategies across different network physical boundaries. For example, a cluster might utilize high-bandwidth All-to-All (Ulysses) intra-node and rely on latency-tolerant Point-to-Point (Ring) inter-node. The precise sizes of these hierarchical tiers are passed directly to configuration engines (e.g., via the hierarchical_context_parallel_sizes list).
Key Takeaways
Internals / Execution Flow
The continuous execution loop for CP operates as follows:
Sharding: A massive 1M token sequence is sliced into  chunks. GPU
chunks. GPU  physically receives Query block
physically receives Query block  , Key block
, Key block  , and Value block
, and Value block  .
.
Local Compute: GPU computes the baseline attention output 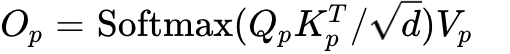 leveraging its local blocks exclusively.
leveraging its local blocks exclusively.
P2P Transfer: GPU executes a network send of  to GPU
to GPU  , whilst simultaneously receiving
, whilst simultaneously receiving  from GPU
from GPU  .
.
Tile Compute: GPU updates its output  utilizing the newly received K/V blocks. This leverages FlashAttention's online softmax normalizer calculation to maintain strict mathematical equivalence.
utilizing the newly received K/V blocks. This leverages FlashAttention's online softmax normalizer calculation to maintain strict mathematical equivalence.
Loop: Steps 3 and 4 iterate until all necessary K/V blocks have fully traversed the communication ring.
Performance Implications
Compute efficiency under CP is highly optimized by deep FlashAttention integration. It successfully avoids up to 30% of the computational overhead traditionally generated by activation recomputation (which is heavily utilized as a crutch in non-CP long-context training paradigms). However, the communication overhead is strictly network bandwidth bound. P2P transfers over the fabric must be meticulously overlapped with the dense  attention tile compute on the Tensor Cores to prevent blocking. Memory per GPU scales near-perfectly as
attention tile compute on the Tensor Cores to prevent blocking. Memory per GPU scales near-perfectly as  .
.