PagedAttention Systems
PagedAttention applies established OS-level virtual memory and paging concepts directly to LLM KV cache management.
Source: mortalapps.com- PagedAttention applies established OS-level virtual memory and paging concepts directly to LLM KV cache management.
- It eliminates the need for contiguous memory allocation, solving massive memory fragmentation issues that previously wasted 60-80% of VRAM.
- KV tensors are divided into fixed-size physical blocks (typically 16 tokens), which are dynamically mapped via a Block Table.
- This architecture fundamentally enables complex memory sharing for techniques like beam search, parallel sampling, and shared prefixes with zero memory overhead.
Why This Matters
Prior to the introduction of PagedAttention by the creators of vLLM, LLM serving engines had to guess the maximum length of a request and allocate a massive contiguous block of GPU memory up front. Because request lengths are highly variable and unpredictable, this led to massive external fragmentation (gaps between contiguous blocks) and internal fragmentation (over-reserved space for tokens that were never generated). This memory waste severely restricted batch sizes, crippling serving throughput and driving up hardware costs exponentially.
Core Intuition
Think of a computer's hard drive without a filesystem—you would have to find a perfectly contiguous empty space large enough for an entire 4K movie before you could save it. Operating systems solved this decades ago using virtual memory and pages. PagedAttention applies this exact paradigm to the GPU's KV cache. It splits the sequence of tokens into small "pages" (blocks). A single conversation can have its tokens scattered across entirely different physical locations in the GPU VRAM, while a "Virtual Block Table" stitches them together sequentially for the attention kernel.
Technical Deep Dive
A typical physical block contains 16 tokens. For a 13B model with a head size of 128, a single block for one head stores 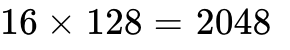 elements. In the logical view, a sequence is perfectly continuous. In the physical view, blocks are completely scattered. A lightweight indirection table (the Block Table) maps logical block indices to physical block indices. During the attention computation, the custom PagedAttention kernel queries this table to fetch the exact memory pointer for the K and V vectors. A CUDA warp (32 threads) processes the calculation between one query token and key tokens of an entire block simultaneously, efficiently managing warp divergence.
elements. In the logical view, a sequence is perfectly continuous. In the physical view, blocks are completely scattered. A lightweight indirection table (the Block Table) maps logical block indices to physical block indices. During the attention computation, the custom PagedAttention kernel queries this table to fetch the exact memory pointer for the K and V vectors. A CUDA warp (32 threads) processes the calculation between one query token and key tokens of an entire block simultaneously, efficiently managing warp divergence.