Streaming Multiprocessor (SM) Architecture
The SM is the atomic unit of GPU compute capability. Blackwell GB100 die (datacenter) contains 132 SMs.
Source: mortalapps.com- The SM is the atomic unit of GPU compute capability.
- Blackwell GB100 die (datacenter) contains 132 SMs.
- Each Blackwell SM features 128 CUDA cores and 4 Fifth-Generation Tensor Cores.
- Key architectural shift: Addition of 256 KB of Tensor Memory (TMEM) per SM specifically for MMA staging.
Why This Matters
To fully utilize a $30,000+ GPU, infrastructure engineers must balance their workload exactly against the SM's physical boundaries. Understanding the exact limits of Register Files, TMEM, SMEM, and execution units prevents catastrophic performance cliffs caused by register spilling or execution starvation.
Core Intuition
Think of the GPU as a massive factory floor, and the SM as an individual assembly line. You can only assign as many workers (threads) to the line as there are lockers (registers) and staging tables (SMEM/TMEM). If you give the workers tools that are too complex (high register usage), you must fire half the workers, leaving the actual assembly machines (Tensor Cores) sitting idle.
Technical Deep Dive
A full Blackwell GB100 die (datacenter) features 132 SMs. (The gaming GB202 die, used in RTX 5090, features 192 SMs but is a distinct product.)16 At the microarchitectural level, a single B200 SM contains:
Compute: 128 CUDA Cores (FP32/INT32), 4 Fifth-Gen Tensor Cores, and 4 Special Function Units (SFUs).
Registers: 64K 32-bit registers, totaling 256 KB.
L1 / SMEM: 228 KB of configurable Shared Memory (Compute 10.0 datacenter).
TMEM: 256 KB of dedicated Tensor Memory.
Blackwell radically rearchitects the memory hierarchy. The 256 KB TMEM is a dedicated SRAM block that is entirely separate from standard SMEM. It acts as a warp-synchronous vault.
Key Takeaways
Performance Implications
Because TMEM handles the massive 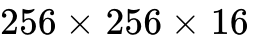 tile accumulations, the register file is unburdened. TMEM achieves approximately 420 clock cycles for accumulator access, versus Hopper's ~1000-cycle HBM latency incurred when register pressure forces accumulator spills to global memory — a 58% reduction in the worst-case accumulation path.
tile accumulations, the register file is unburdened. TMEM achieves approximately 420 clock cycles for accumulator access, versus Hopper's ~1000-cycle HBM latency incurred when register pressure forces accumulator spills to global memory — a 58% reduction in the worst-case accumulation path.
Common Bottlenecks
Resource Exhaustion: Launching kernels requiring 150 KB of SMEM means only one thread block can fit on a B200 SM (since 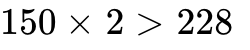 KB limit). This destroys occupancy.
KB limit). This destroys occupancy.