SmoothQuant Outlier Suppression
SmoothQuant is a mathematically exact, training-free technique that smooths activation outliers by safely transferring their magnitude to the model's
Source: mortalapps.com- SmoothQuant is a mathematically exact, training-free technique that smooths activation outliers by safely transferring their magnitude to the model's static weights offline.
- The core purpose is to enable high-throughput W8A8 (8-bit weight, 8-bit activation) quantization using standard, unmodified integer GEMM hardware kernels.
- The primary optimization relies on a per-channel scaling factor that mathematically divides the problematic activations and proportionally multiplies the stable weights.
- The essential engineering insight is that scaling activations per-channel dynamically at runtime violates hardware GEMM mechanics; SmoothQuant solves this by baking the scale into the model architecture statically before deployment.
Why This Matters
While W4A16 quantization alleviates memory bus bottlenecks, it does not accelerate the underlying mathematical computation. To unlock the massive arithmetic density of integer Tensor Cores (INT8), both the inputs to the matrix multiplier—weights and activations—must be quantized. Since systematic activation outliers completely destroy standard per-tensor INT8 quantization (collapsing all normal values to zero), and dynamic outlier extraction methods are prohibitively slow, SmoothQuant provides the mathematically pure, static solution to achieve true W8A8 compute-bound speedups.
Core Intuition
Think of a neural pathway as a water pipe. The activation is the water pressure, and the weight is the physical valve. If the pressure spikes massively in one specific channel (an outlier), the pipe bursts (quantization clipping). However, we can proactively widen the pipe before the valve (divide the activation by a factor  ) and tighten the valve exactly proportionally (multiply the weight by ). The net flow (the output) remains mathematically identical, but the internal pressure spike is neutralized. SmoothQuant fundamentally "migrates" the quantization difficulty from the volatile activations to the stable, highly accommodating weights.
) and tighten the valve exactly proportionally (multiply the weight by ). The net flow (the output) remains mathematically identical, but the internal pressure spike is neutralized. SmoothQuant fundamentally "migrates" the quantization difficulty from the volatile activations to the stable, highly accommodating weights.
Technical Deep Dive
For a standard linear layer computation  , SmoothQuant introduces a static, per-channel smoothing vector . The transformation is expressed as:
, SmoothQuant introduces a static, per-channel smoothing vector . The transformation is expressed as:
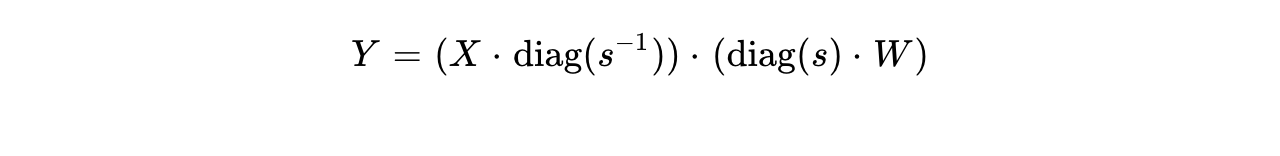
By defining 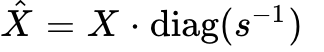 and
and 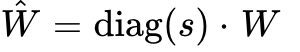 , the system isolates the outliers.
, the system isolates the outliers.
Now,  features suppressed outliers, making it highly amenable to per-token (or per-tensor) INT8 quantization. Concurrently,
features suppressed outliers, making it highly amenable to per-token (or per-tensor) INT8 quantization. Concurrently,  absorbs the magnitude but remains easy to quantize using per-channel weight scales.
absorbs the magnitude but remains easy to quantize using per-channel weight scales.
At runtime, the optimized execution is simply:
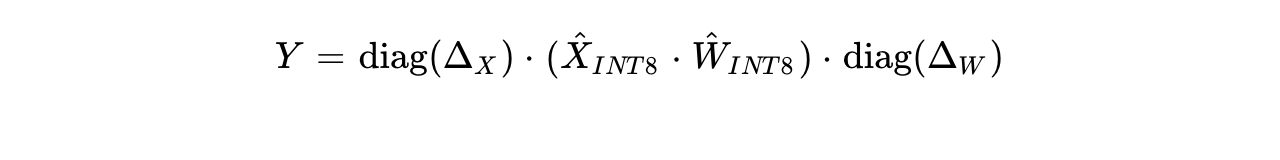
where  represents the floating-point dequantization scales applied after the fast integer matrix multiplication finishes.
represents the floating-point dequantization scales applied after the fast integer matrix multiplication finishes.
Key Takeaways
 ).
). hyperparameter to dynamically balance the quantization difficulty between matrices.
hyperparameter to dynamically balance the quantization difficulty between matrices.Internals / Execution Flow
The offline compilation process involves four distinct steps:
Calibration: Execute a sample dataset to locate the absolute maximum value per channel across the activations, extracting  .
.
Smoothing Factor Calculation: Generate the smoothing vector using the formula:
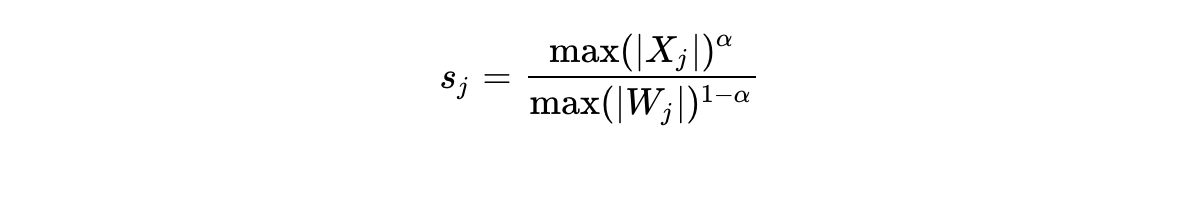
where is a tunable hyperparameter controlling how much scaling difficulty is shifted onto the weights.
Offline Adjustment: Statically update the weights: . The inverse scale  is physically absorbed into the bias or weights of the preceding layer (e.g., LayerNorm or RMSNorm).
is physically absorbed into the bias or weights of the preceding layer (e.g., LayerNorm or RMSNorm).
Runtime Execution: Pass the naturally smoothed activations directly into standard INT8 cuBLAS IGEMM routines.
Common Bottlenecks
If the hyperparameter is set incorrectly, migrating too much outlier mass into the weights will cause the weights themselves to drastically exceed their INT8 quantization bounds, destroying network accuracy. The parameter must be empirically tuned per model family (for example, LLaMA architectures generally optimize perfectly at  ).
).
Tools & Frameworks
The open-source smoothquant GitHub repository provides automated transformation scripts. Modern model exporters natively detect standard attention block architectures and automatically fuse the  scales into the adjacent normalization weights.
scales into the adjacent normalization weights.