Global Memory Coalescing Techniques
Global memory coalescing aligns memory requests from adjacent threads within a warp into a single, highly efficient memory transaction.
Source: mortalapps.com- Global memory coalescing aligns memory requests from adjacent threads within a warp into a single, highly efficient memory transaction.
- The core purpose is to maximize global memory bus utilization and aggressively minimize unnecessary data transfers, known as over-fetch.
- The primary optimization idea is aligning thread access patterns sequentially across contiguous memory blocks based on cache-line boundaries.
- The most important engineering insight is that uncoalesced accesses can waste over 85% of VRAM bandwidth, transforming otherwise compute-bound AI kernels into severe memory bottlenecks.
Why This Matters
With modern architectures boasting massive theoretical memory bandwidth—such as the 4.8 TB/s provided by the H200 1—achieving this peak performance in reality is entirely contingent on coalescing. Uncoalesced accesses force the GPU memory controller to fetch unnecessary bytes simply to satisfy small, scattered requests. This behavior crushes effective throughput and drives up L2 cache thrashing, starving the multiprocessors.
Core Intuition
Think of global memory access like a freight train carrying massive shipping containers (cache lines). If an operation requires 32 specific items, it is vastly more efficient if all 32 items are located inside the exact same container. If the 32 items are scattered across 32 different containers, the train must transport all 32 massive containers just to extract the small items inside, resulting in catastrophic waste of transport capacity.
Technical Deep Dive
A warp comprises 32 parallel threads. The L1 cache fetches data from memory in 128-byte cache lines, which map perfectly to four 32-byte aligned segments in the physical device memory. Crucially, memory accesses that are forced to bypass L1 and are cached in L2 only (uncached loads) are serviced with smaller 32-byte memory transactions.
When a warp requests a memory address, the hardware coalescing unit determines which 32-byte or 128-byte segments contain the requested bytes. In Ideal Coalescing, all 32 threads access sequential 4-byte values starting at an address aligned to a multiple of 32 bytes. The warp requests exactly 128 bytes, and exactly one 128-byte cache line is fetched, resulting in 100% bus utilization. Conversely, under an Uncoalesced Penalty, if the threads request 4-byte words scattered randomly across memory, the GPU might fetch 32 distinct 32-byte segments (1024 bytes loaded) to serve the 128 bytes of required data. The efficiency immediately plummets to 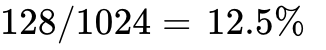 .
.