Online Softmax Computation
Standard Softmax algorithms require loading the full row of data twice to compute the maximum value (for stability) and the sum of exponentials, creating
Source: mortalapps.com- Standard Softmax algorithms require loading the full row of data twice to compute the maximum value (for stability) and the sum of exponentials, creating massive memory overhead.
- Online Softmax computes the operation incrementally in distinct blocks, allowing the memory complexity of the algorithm to drop exponentially from
 to
to  .
. - It utilizes a specific mathematical scaling factor,
 , to algorithmically update running sums and outputs whenever a new block introduces a higher maximum value.
, to algorithmically update running sums and outputs whenever a new block introduces a higher maximum value. - This precise mathematical breakthrough is the foundational engine driving the FlashAttention algorithm, enabling infinite context LLMs.
Why This Matters
In standard Transformer architectures, computing Attention mathematically requires generating a massive  matrix (Sequence Length
matrix (Sequence Length  Sequence Length) representing the interaction scores between all possible tokens. For a sequence length of 100K tokens, this natively requires storing 10 billion FP16 elements (~20GB) just to hold the intermediate softmax state. This makes long-context models physically impossible to run inside fast SRAM. Online Softmax mathematically restructures the operation so the massive matrix is never fully materialized in HBM, revolutionizing LLM efficiency and making modern context windows viable.
Sequence Length) representing the interaction scores between all possible tokens. For a sequence length of 100K tokens, this natively requires storing 10 billion FP16 elements (~20GB) just to hold the intermediate softmax state. This makes long-context models physically impossible to run inside fast SRAM. Online Softmax mathematically restructures the operation so the massive matrix is never fully materialized in HBM, revolutionizing LLM efficiency and making modern context windows viable.
Core Intuition
Calculating standard Softmax is conceptually like trying to grade a test on a complex curve. The grader must first look at every single student's score in the entire school to find the absolute maximum. Then, they must look at everyone's score again to sum the adjusted scores, and finally look a third time to assign the final grade. If you have 1 million students, you physically cannot fit them all in the grading room (SRAM). Online Softmax lets the grader process students precisely as they walk through the door. The grader keeps a "running maximum" and a "running sum." If a new student walks in with a score higher than the current maximum, the grader applies a mathematical discount (a scale factor) to the running sum and output to retroactively correct them. This elegantly updates the grading history without ever needing to see the old students again.
Technical Deep Dive
Standard Softmax strictly requires numerical stabilization due to the threat of exponential overflow (where computing  results in inf). It relies on the mathematical property of shift-invariance 10:
results in inf). It relies on the mathematical property of shift-invariance 10:
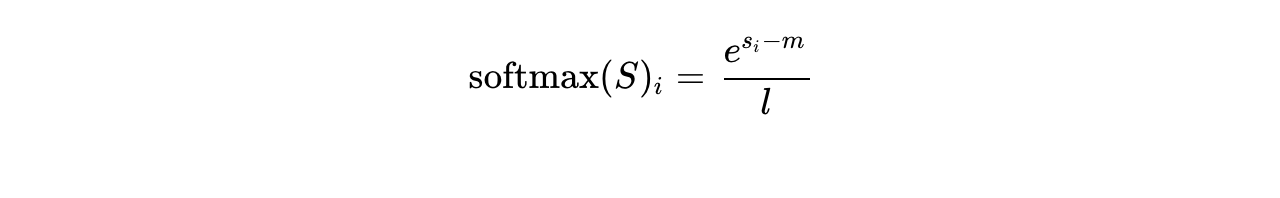
where  and
and  .
.
To process calculations in sub-blocks (tiles) without losing mathematical correctness, the algorithm maintains active running statistics in registers:  (maximum),
(maximum),  (denominator sum), and
(denominator sum), and  (unnormalized output).
(unnormalized output).
When transitioning calculation from Block A (featuring an old max  ) to Block B (featuring a new local max
) to Block B (featuring a new local max  ):
):
New Global Max: Evaluate 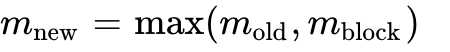 .
.
Rescaling Factor: The exact algebraic relationship between exponentials shifted by different maximums is exactly the factor  . Because
. Because  is guaranteed to be
is guaranteed to be  , this scale factor is always
, this scale factor is always  , structurally preventing overflow.
, structurally preventing overflow.
State Update: We multiply the previous states to logically reflect the new maximum baseline:
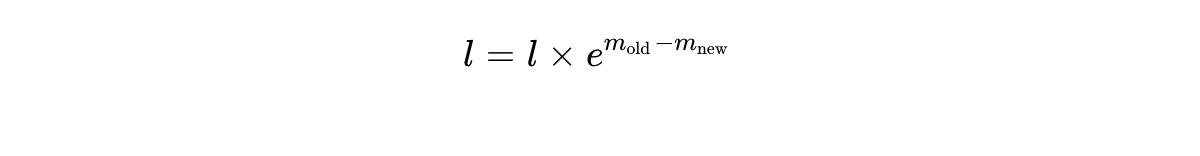
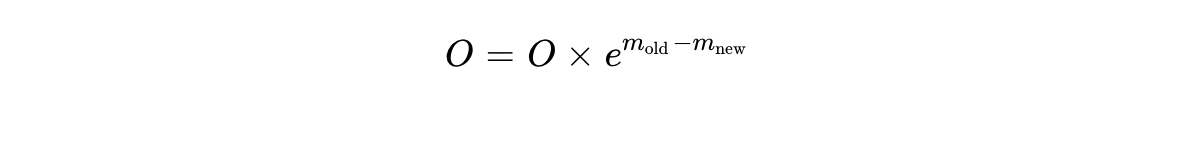
Accumulate: Compute the exponentials specifically for the new block using , add them to , and accumulate the new weighted sum into . Finally, divide by to yield the mathematically exact normalized output.
Key Takeaways
perfectly updates previous running sums to the new maximum, maintaining strict mathematical equivalence to standard Softmax., ensuring absolute numerical stability. memory bottleneck of transformers.Internals / Execution Flow
Executing Online Softmax efficiently involves tightly coupled register tracking.
| Execution Step | Algorithmic Action |
|---|---|
| Hardware Mapping | Initialization |
Set running variables  , ,  , ,  . . | Bound to ultra-fast SRAM registers. |
| SRAM Load | Load Block 1 (Queries, Keys, Values) from HBM to SRAM. |
| Executes via asynchronous bulk copy (TMA). | Matmul |
Compute raw attention scores  strictly for the loaded block. strictly for the loaded block. | Evaluated efficiently on Tensor Cores. |
| Local Statistics | Scan to find the local maximum . |
| Thread-level evaluation. | Update State |
Calculate , derive the scaling factor  , and mathematically scale and . , and mathematically scale and . | Arithmetic scaling in registers. |
| Accumulate | Compute  , update , update  , update , update  . . |
| Accumulates data without HBM trips. | Iterate & Finalize |
Repeat for all sequence blocks; write out  directly to HBM. directly to HBM. | Outputs finalized attention result. |
Performance Implications
| The performance implications define the modern LLM era. | Performance Metric | Operational Impact |
|---|---|---|
| Memory Bandwidth | Architecturally drops memory reads/writes to . The algorithm definitively becomes compute-bound rather than memory-bound. | SRAM Utilization |
Because the required data footprint at any one moment is just a tiny tile block (e.g.,  ), it fits entirely inside the ultra-fast L1 Cache / Shared Memory. ), it fits entirely inside the ultra-fast L1 Cache / Shared Memory. | Hardware FLOPs | Computes slightly more FLOPs than standard attention (due to continuous rescaling overhead), but executes exponentially faster because it entirely bypasses HBM latency. |
Common Bottlenecks
A critical failure point is Tile Sizing. If the block sizes chosen by the compiler are too large, the required state variables mathematically spill out of SRAM into HBM, entirely defeating the foundational purpose of the algorithm. Furthermore, the Reduction Dependency is a severe bottleneck; the requirement to constantly update the running maximum creates a tight data dependency loop. Instruction scheduling must be meticulously optimized to prevent SM pipeline stalls while actively computing the block maximum.
Interview Guidance
In tier-one infrastructure interviews, possessing mathematical competence is critical. Knowing the specific scaling factor and being able to mathematically prove the shift-invariance property of Softmax on a whiteboard is a top-tier interview question for AI Kernel Engineers. Furthermore, understanding precisely how this algorithmic trick bridges abstract algorithmic mathematics and hard physical hardware constraints (SRAM vs HBM limits) demonstrates elite architectural intuition.