Speculative Decoding Systems
Speculative decoding exploits the memory-bound nature of the decode phase by shifting from sequential generation to parallel "draft-then-verify."
Source: mortalapps.com- Speculative decoding exploits the memory-bound nature of the decode phase by shifting from sequential generation to parallel "draft-then-verify."
- A smaller model rapidly predicts
 tokens; the large model verifies them in a single compute-dense forward pass.
tokens; the large model verifies them in a single compute-dense forward pass. - Turns idle GPU FLOPs into latency reduction without altering the output probability distribution.
Why This Matters
During standard decode, expensive GPU ALUs sit idle waiting for memory. Speculative decoding allows engineers to trade this wasted compute capacity for massive reductions in latency. It effectively breaks the autoregressive bottleneck, yielding 2x to 6.5x speedups in tokens/sec for a single request, which is vital for real-time voice and interactive agents.
Core Intuition
Instead of asking a senior engineer to write a document one word at a time, you have an intern (draft model) rapidly write a full paragraph. The senior engineer (target model) reads the paragraph instantly and approves it up to the first mistake. Because reading is faster than writing, the overall process accelerates, and the final quality is identical to the senior engineer's writing.
Technical Deep Dive
The small draft model generates tokens. The target model takes all tokens and executes a single forward pass (GEMM). It compares its computed logits against the drafted tokens. If 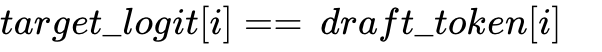 , the token is accepted. If a token is rejected at position
, the token is accepted. If a token is rejected at position  , tokens through are discarded, and the correct token generated by the target model at position is used. To prevent wasted compute during low acceptance, Pipeline-Parallel Speculative Decoding (PPSD) interleaves drafting and verification at the micro-token level, achieving speedup ratios up to
, tokens through are discarded, and the correct token generated by the target model at position is used. To prevent wasted compute during low acceptance, Pipeline-Parallel Speculative Decoding (PPSD) interleaves drafting and verification at the micro-token level, achieving speedup ratios up to  .
.
Key Takeaways
Internals / Execution Flow
Draft Phase: Draft mechanism generates tokens  sequentially.
sequentially.
Parallel Forward: Target model loads the sequence  and computes hidden states in parallel.
and computes hidden states in parallel.
Verification: System evaluates acceptance criteria (greedy matching or stochastic sampling bounds).
Correction: System accepts tokens up to the first failure, appends the correct target token, and updates the KV cache, discarding invalid branches.
Loop: Process restarts from the newly verified position.