Tensor Core Execution Systems
Tensor Cores are specialized matrices-math hardware units. Blackwell (B200) houses 5th Generation Tensor Cores.
Source: mortalapps.com- Tensor Cores are specialized matrices-math hardware units.
- Blackwell (B200) houses 5th Generation Tensor Cores.
- Supports microscaling formats: FP4, FP6, FP8, and NVFP4.22
- Delivers an unprecedented 20 petaFLOPS of FP4 compute per GPU.
Why This Matters
AI scaling laws demand exponential increases in compute density. Traditional FP32 operations cap out too early. Tensor Cores, specifically through low-precision formats, unlock the mathematical density required to run trillion-parameter architectures in real-time. Without mastering Tensor Core capabilities, an infrastructure engineer cannot correctly size or configure deployment clusters.
Core Intuition
A standard CUDA core multiplies two numbers in one clock cycle (Scalar). A Tensor Core multiplies two entire blocks of numbers (e.g., a  or
or  grid) and adds them to a third block in a single clock cycle (Matrix). By dropping the precision from 16-bit to 8-bit or 4-bit, the hardware can fit exponentially more numbers into the same physical silicon area, doubling throughput with each halving of precision.
grid) and adds them to a third block in a single clock cycle (Matrix). By dropping the precision from 16-bit to 8-bit or 4-bit, the hardware can fit exponentially more numbers into the same physical silicon area, doubling throughput with each halving of precision.
Technical Deep Dive
The 5th-generation Tensor Cores in Blackwell feature the 2nd-generation Transformer Engine. A B200 GPU achieves:
| 20 PFLOPS of FP4 (dense; 40 PFLOPS with 2:4 sparsity) | 10 PFLOPS of FP8 / FP6 (dense; 20 PFLOPS sparse) |
|---|---|
| 10 POPS of INT8 (dense; 20 POPS sparse) | 5 PFLOPS of FP16 / BF16 (dense; 10 PFLOPS sparse) |
The PTX instruction tcgen05.mma.cta_group::[1|2].kind::f8f6f4 orchestrates this. It can execute across a single SM or cooperatively across two SMs (cta_group::2). The architecture supports block-scaled data types like float_ue8m0_t and float_ue4m3_t natively, which allows narrow 4-bit types to retain dynamic range by applying a shared scaling factor to the block.
Key Takeaways
Optimization Strategies
Pad all matrix dimensions to multiples of 16.
Keep data in lower precision as long as possible; only upcast to FP32 in the register file just before applying transcendental activation functions (like Softmax).
Utilize 2-SM cooperative tcgen05.mma to maximize the tile shape to 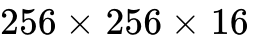 for massive GEMMs.
for massive GEMMs.