Matrix Multiplication (GEMM) Execution Mechanics
GEMM is bounded by memory logistics, not just raw FLOPs. Execution requires hierarchical tiling: High-Bandwidth Memory (HBM) L2 Cache Shared Memory (SMEM)
Source: mortalapps.com- GEMM (
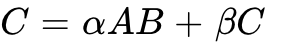 ) is bounded by memory logistics, not just raw FLOPs.
) is bounded by memory logistics, not just raw FLOPs. - Execution requires hierarchical tiling: High-Bandwidth Memory (HBM)
 L2 Cache Shared Memory (SMEM) Tensor Memory (TMEM) / Registers.
L2 Cache Shared Memory (SMEM) Tensor Memory (TMEM) / Registers. - Hopper standardized the Warp Group Matrix Multiply and Accumulate (WGMMA), while Blackwell introduces Universal Matrix Multiply and Accumulate (UMMA) via tcgen05.mma.
- The most critical engineering insight: Peak teraFLOPS are only achieved when intermediate accumulation state strictly bypasses the GPU register file to prevent register spilling.
Why This Matters
At scale, a trillion-parameter LLM forward pass is essentially a distributed chain of massive GEMMs. Infrastructure engineers must map these logical matrix operations to the physical GPU hierarchy. Failing to optimize GEMM execution mechanics leads to register spilling, memory bandwidth saturation, and cluster-wide compute stalls, directly translating to millions of dollars in wasted data center power and inflated latency metrics.
Core Intuition
Think of GEMM not as math, but as a supply chain problem. The mathematical execution (multiplying and adding) takes a single clock cycle on a Tensor Core. However, fetching the operands from HBM takes hundreds of cycles. The core intuition is "Data Staging": we must break the massive matrices into block tiles, fetch them asynchronously, and compute on the current tile while the next tile is in flight, storing the intermediate sums in the closest physical memory possible.
Technical Deep Dive
Historically, Hopper architectures relied on WGMMA operations (max shape 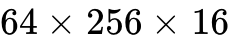 ), utilizing four warps to accumulate data into the register file. Blackwell revolutionizes this by expanding the UMMA block shape to an unprecedented
), utilizing four warps to accumulate data into the register file. Blackwell revolutionizes this by expanding the UMMA block shape to an unprecedented 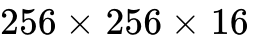 , spanning two Streaming Multiprocessors (SMs). Furthermore, Blackwell entirely shifts the target for accumulated matrices (
, spanning two Streaming Multiprocessors (SMs). Furthermore, Blackwell entirely shifts the target for accumulated matrices ( and
and  ) from thread registers into a dedicated 256 KB Tensor Memory (TMEM) subsystem using the tcgen05 PTX instruction family.
) from thread registers into a dedicated 256 KB Tensor Memory (TMEM) subsystem using the tcgen05 PTX instruction family.
Key Takeaways
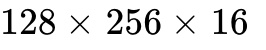 (single SM) or (dual SM).
(single SM) or (dual SM).Interview Guidance
Candidates for AI systems roles are frequently asked to whiteboard the memory hierarchy of a GEMM. Strong engineers know that computing matrix multiplication is bound by SRAM/HBM bandwidth, whereas weak engineers only cite big-O algorithmic complexity ( ). Knowing the shift from register-accumulation (Hopper) to TMEM (Blackwell) sets top candidates apart.
). Knowing the shift from register-accumulation (Hopper) to TMEM (Blackwell) sets top candidates apart.