AWQ Quantization Systems
Activation-Aware Weight Quantization (AWQ) is a training-free technique that protects the neural network's most critical 1% of weights by scaling them up
Source: mortalapps.com- Activation-Aware Weight Quantization (AWQ) is a training-free technique that protects the neural network's most critical 1% of weights by scaling them up prior to quantization.
- The core purpose is to achieve highly accurate W4A16 quantization without the latency penalties of mixed-precision data paths or the overfitting risks of backpropagation-based calibration.
- The primary optimization is identifying the network's salient weights based entirely on their corresponding activation magnitude, rather than the magnitude of the weights themselves.
- The most important engineering insight is that scaling a salient weight channel up artificially reduces its relative quantization error, mathematically shielding the network's most critical pathways from degradation.
Why This Matters
Prior to the introduction of AWQ, quantization methods like GPTQ relied heavily on complex Hessian matrix calculations. These methods were computationally intensive, prone to overfitting the calibration dataset, and often struggled with cross-domain generalization (e.g., maintaining accuracy on both coding and mathematical reasoning). AWQ provides a paradigm shift by relying strictly on forward-pass activation statistics without any backpropagation. It allows highly accurate 4-bit deployment on edge devices and consumer desktops, achieving >3x speedups over FP16 baselines.
Core Intuition
In a massive parameter matrix, not all weights hold equal importance. If you severely degrade the specific 1% of weights that happen to process the largest incoming activation values, the entire network's mathematical output collapses. However, if you attempt to preserve those specific weights in FP16 (as in dynamic mixed-precision routing), you introduce massive hardware inefficiency. Instead, AWQ manipulates the quantization grid itself. If you take an important weight and scale it up (multiplying it by a factor  ) before quantization, the discrete integer bins fit tighter around it. Mathematically, the fractional quantization error
) before quantization, the discrete integer bins fit tighter around it. Mathematically, the fractional quantization error  applied to that specific weight is effectively reduced by the inverse of the scale
applied to that specific weight is effectively reduced by the inverse of the scale  .
.
Technical Deep Dive
To maintain pure mathematical equivalence across the network, if a weight channel is scaled up by a vector  , the incoming activation channel must be scaled down by during the runtime execution.
, the incoming activation channel must be scaled down by during the runtime execution.
AWQ automates the search for this optimal scaling vector  by minimizing an optimization surrogate:
by minimizing an optimization surrogate:
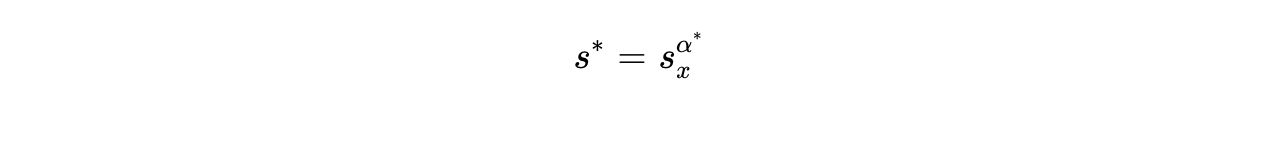
Here,  represents the average magnitude of the input activations (derived quickly from a tiny calibration dataset), and
represents the average magnitude of the input activations (derived quickly from a tiny calibration dataset), and  is a hyperparameter determined via a localized grid search. The algorithm iterates
is a hyperparameter determined via a localized grid search. The algorithm iterates  through the range $$. By finding the that yields the lowest mean squared error between the quantized output and the FP16 reference output, AWQ systematically protects the weights that interact with the largest activations without invoking complex gradients.
through the range $$. By finding the that yields the lowest mean squared error between the quantized output and the FP16 reference output, AWQ systematically protects the weights that interact with the largest activations without invoking complex gradients.
Key Takeaways
Internals / Execution Flow
The offline AWQ preparation follows a distinct sequence:
Profile Activations: A small calibration set (e.g., 128 sequences) is passed through the FP16 model to compute , the average magnitude of input activations for each linear layer.
Grid Search Iteration: The system tests multiple values of $\alpha \in $, computing temporary scales  .
.
Scale Application: The temporary scale is applied:  .
.
Quantization & Error Measurement:  is grouped and quantized into INT4 (either symmetrically or asymmetrically). The output is compared to the baseline, and the minimizing the MSE is permanently selected.
is grouped and quantized into INT4 (either symmetrically or asymmetrically). The output is compared to the baseline, and the minimizing the MSE is permanently selected.
Bake Offline: The selected inverse scales are physically absorbed into the preceding layer's operators (such as LayerNorm or RMSNorm) offline, removing them from the runtime pathway entirely.
Optimization Strategies
To squeeze the maximum accuracy out of the 4-bit limit, AWQ pipelines heavily favor asymmetric quantization over symmetric quantization. Asymmetric quantization utilizes a true minimum and a true maximum  to map the exact interval of the data into the integer bins, capturing skewed distributions perfectly. While this requires tracking a distinct zero-point
to map the exact interval of the data into the integer bins, capturing skewed distributions perfectly. While this requires tracking a distinct zero-point  and adds minor computational overhead during the register dequantization phase, the accuracy recovery is essential.
and adds minor computational overhead during the register dequantization phase, the accuracy recovery is essential.