Low-Precision Matrix Multiplication
Low-precision matrix multiplication (GEMM) leverages specialized GPU Tensor Cores to execute massive dot-products in FP8, INT8, or FP4 formats directly in
Source: mortalapps.com- Low-precision matrix multiplication (GEMM) leverages specialized GPU Tensor Cores to execute massive dot-products in FP8, INT8, or FP4 formats directly in silicon.
- The core purpose is to vastly increase peak TFLOPS (arithmetic density) and fundamentally reduce memory bus traffic.
- The primary optimization is two-level software-hardware accumulation, maintaining intermediary sums in high-precision (FP32) to prevent precision collapse during the massive dot product reductions.
- The essential engineering insight is that low-precision math is only fast if data delivery keeps pace; memory-bound "skinny" matrices must implement SplitK algorithms to parallelize work across thread blocks effectively.
Why This Matters
Generative AI scaling laws demand exponentially more computation per generation. The latest Blackwell B200 GPU achieves,000 TFLOPS (20 PFLOPS) operating in NVFP4 (dense, non-sparsity) — doubling to 40 PFLOPS with 2:4 structured sparsity, compared to only a fraction of that in FP16.10 System software engineers must write the complex custom kernels that coerce the underlying Tensor Cores to actually operate continuously in these formats, otherwise, the massive multi-billion-dollar silicon investment is entirely wasted by software bottlenecks.
Core Intuition
A matrix multiplication is fundamentally a sequence of millions of multiply-and-accumulate (MAC) operations. If you multiply two 4-bit numbers, the output is relatively small. But as you add thousands of these tiny products together (the dot product reduction), the sum rapidly overflows the strict bounds of a 4-bit or 8-bit format. Hardware architects solve this physical constraint by performing the multiplication in the low-precision format, but actively accumulating (adding) the resultant products in a wide, high-precision 32-bit register.
Technical Deep Dive
On Hopper and Blackwell architectures, low-precision GEMMs rely on deep architectural primitives:
Instruction Sets: The mma.sync PTX instructions strictly orchestrate the Thread Block's matrix math.
Warp Schedulers: A warp consists of 32 threads, and the scheduler issues highly coordinated load, store, and multiply instructions to all 32 threads simultaneously per clock cycle.
Accumulator Precision: For FP8 and FP4 inputs, the 5th generation Tensor Cores accumulate results internally in FP32 to completely negate intermediate overflow.
However, for memory-bound "skinny" matmuls (e.g., an inference decoding step with a batch size of 1 to 16), a standard Data Parallel (DP) decomposition leaves the majority of the GPU hardware idle. To solve this, kernel engineers utilize the SplitK algorithm. SplitK forcefully divides the inner reduction dimension ( ) across multiple Thread Blocks. Each independent block computes a partial FP32 sum, and a final reduction kernel rapidly adds these partial sums together before writing to memory.
) across multiple Thread Blocks. Each independent block computes a partial FP32 sum, and a final reduction kernel rapidly adds these partial sums together before writing to memory.
Key Takeaways
Internals / Execution Flow
Executing a custom low-precision GEMM requires precise orchestration:
Fetch: Load packed low-precision weights and activations from HBM to Shared Memory (SMEM).
Decompress/Dequantize: If executing a W4A16 GEMM, the INT4 weights are bit-shifted and expanded into FP16 formats strictly within the fast registers.
Execute: Tensor Cores perform the highly parallel  tile multiplications.
tile multiplications.
Epilogue: The FP32 accumulators are multiplied by the required dequantization scales, mathematically cast back to FP16 or FP8, and written securely to global memory.
Optimization Strategies
Kernel engineers heavily tune tile configurations (e.g., defining grids of 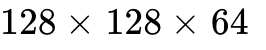 ) to maximize L2 cache hit rates while keeping register usage strictly under the architectural limit of 255 registers per thread. Furthermore, sophisticated software emulation is employed on Blackwell to decompose complex, unsupported matrix operations, leveraging the high-throughput lower-precision cores to match IEEE754 accuracy via fixed-point software logic.
) to maximize L2 cache hit rates while keeping register usage strictly under the architectural limit of 255 registers per thread. Furthermore, sophisticated software emulation is employed on Blackwell to decompose complex, unsupported matrix operations, leveraging the high-throughput lower-precision cores to match IEEE754 accuracy via fixed-point software logic.