Time-To-First-Token (TTFT) Optimization
TTFT is the foundational latency metric for interactive AI, driven primarily by the Prefill computation phase.
Source: mortalapps.com- TTFT is the foundational latency metric for interactive AI, driven primarily by the Prefill computation phase.
- Optimizing TTFT in a distributed environment requires dedicated prefill GPU pools and ultra-fast network handoffs.
- Network math dictates architectural viability: slow ethernet fundamentally breaks disaggregated TTFT.
Why This Matters
In chat interfaces or agentic loops, TTFT dictates perceived system responsiveness. If an autonomous agent must query an LLM 50 times in a loop, a 2-second TTFT per call adds nearly two minutes of dead time. Strict TTFT SLAs (e.g., <500ms) dictate the hardware topology of the entire data center.
Core Intuition
Optimizing TTFT is about optimizing the very first heavy lift. If you have a factory, TTFT is how fast you can process the raw materials into the first component. You dedicate massive, high-power machinery (Prefill nodes) exclusively to that first step, and pass the component down a high-speed conveyor belt (InfiniBand) to the assembly workers (Decode nodes).
Technical Deep Dive
As established, a LLaMA-3.1-70B model requires 1.34 GB of KV cache for a 4K prompt (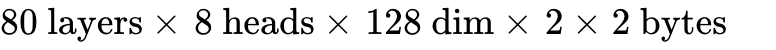 ). If the TTFT SLO is 500ms, and the Tensor Cores take 200ms to compute the GEMM, the network handoff to the Decode node must take <300ms.
). If the TTFT SLO is 500ms, and the Tensor Cores take 200ms to compute the GEMM, the network handoff to the Decode node must take <300ms.
| 1 GbE: 10.7 seconds 5 | 10 GbE: 1.07 seconds 5 |
|---|---|
| 100 GbE: 110 ms 5 | InfiniBand HDR: 54 ms 5 |
NVLink: 2.2 ms 5 Therefore, meeting enterprise TTFT guarantees necessitates 100 GbE+ or InfiniBand interconnects.