GPU Hardware Generations (H100 → B200 → Future Architectures)
Blackwell (GB200/B200) represents a systemic leap over Hopper (H100). Dual-die architecture pushing 208 Billion transistors.
Source: mortalapps.com- Blackwell (GB200/B200) represents a systemic leap over Hopper (H100).
- Dual-die architecture pushing 208 Billion transistors.
- Massive shift from register-bound math (WGMMA) to TMEM-bound math (UMMA, tcgen05.mma).
- Future architectures predict on-package HBM, optical interconnects, and <4-bit precision.
Why This Matters
AI infrastructure is hardware-dictated. Code written optimally for Hopper (WGMMA) will run sub-optimally on Blackwell if it doesn't pivot to use Tensor Memory (TMEM). Engineers must anticipate hardware trajectories to design software stacks that scale seamlessly into future data centers.
Core Intuition
Hopper was about making the engine (Tensor Cores) as fast as possible and adding a fuel pump (TMA). Blackwell is about realizing the engine is so fast that the internal plumbing (Registers and SMEM) is bursting. Blackwell adds a massive dedicated fuel tank (TMEM) right next to the engine and a decompression system (DE) to squeeze more fuel through the pipes.
Technical Deep Dive
| Hopper (H100): | Introduced TMA (Async copy). |
|---|---|
Relied on wgmma (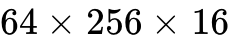 ) accumulating into the Register File. ) accumulating into the Register File. | 1st Gen Transformer Engine (FP8). |
| Blackwell (B200 / GB100): | Dual-die architecture, 104 Billion transistors per die (208B total). |
| 192 GB of HBM3e yielding 8.0 TB/s bandwidth. | Replaces wgmma with tcgen05.mma (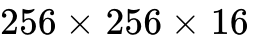 ), offloading accumulation to the 256 KB TMEM. ), offloading accumulation to the 256 KB TMEM. |
| Hardware Decompression Engine (DE) to multiply effective memory bandwidth. | 2nd Gen Transformer Engine (FP4, NVFP4). |
NVLink scalable to 130 TB/s in the NVL72 rack domain.