Auto-Tuning and Kernel Search Spaces
Auto-tuning is the automated, empirical process of sweeping through a combinatorial search space of kernel configurations to discover the optimal hardware
Source: mortalapps.com- Auto-tuning is the automated, empirical process of sweeping through a combinatorial search space of kernel configurations to discover the optimal hardware execution parameters.
- It dynamically determines critical physical variables like block sizes (BLOCK_M, BLOCK_N), warp counts, and pipeline execution stages.
- The @triton.autotune decorator seamlessly enables kernel-level profiling and persistent caching of the most efficient configurations.
- Auto-tuning fundamentally bridges the gap between hardware-agnostic compiler IRs and the highly specific, physical limitations of silicon (such as SM counts and register sizes).
Why This Matters
Even the most sophisticated AI compilers (like MLIR or TorchInductor) rely on generalized heuristics to determine how to tile data for parallel processing. However, physical hardware architecture varies wildly between an NVIDIA Ampere, an NVIDIA Hopper, and an AMD MI300X (which uniquely features 304 CUs and 64-thread wavefronts). A specific block size that perfectly saturates an H100 may cause catastrophic register spilling on an A100. Auto-tuning brute-forces this problem by empirically executing and benchmarking configurations on the actual silicon, guaranteeing near-expert hardware utilization without requiring painstaking manual profiling.
Core Intuition
Think of auto-tuning exactly like tuning a highly complex race car's suspension for a specific track surface. You have three primary dials: tire pressure, ride height, and camber angle (equivalent to Block Size, Num Warps, and Num Stages). You do not know the mathematically perfect combination in advance. Instead, you drive a lap with setting A, then drive a lap with setting B, and meticulously record the lap times. Auto-tuning systematically tests these combinations during a defined "warm-up" phase, records the fastest lap time, and irrevocably locks in those specific settings for the actual race.
Technical Deep Dive
A kernel's configuration search space is inherently combinatorial. If the autotuner sweeps BLOCK_SIZE across 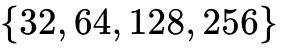 , num_warps across
, num_warps across  , and num_stages across
, and num_stages across  , there are dozens of distinct permutations to evaluate.
, there are dozens of distinct permutations to evaluate.
When the Triton compiler encounters the @triton.autotune decorator, it does not guess; it generates a unique PTX/cubin binary for each valid configuration provided in the configs list. During the very first execution (the JIT cache miss), Triton sequentially launches all generated kernels loaded with dummy data. It measures the execution latency (using high-precision CUDA events), algorithmically selects the configuration yielding the minimum latency, and caches this selection permanently, mapping it strictly to the input tensor's shape signature. Advanced auto-tuning logic (such as the max-autotune mode in PyTorch Inductor) expands this search to swap underlying code emitters entirely, benchmarking a native ATen kernel against a generated Triton implementation and a proprietary cuBLAS call, selecting the absolute fastest variant.
Key Takeaways
Optimization Strategies
To accelerate tuning, engineers implement heuristic-based pruning to limit the search space (e.g., if a matrix dimension  , the tuner immediately discards evaluating
, the tuner immediately discards evaluating  ). Modern, state-of-the-art approaches (like Ansor or specific MLIR tuning passes) utilize Machine Learning reinforcement models or cost modeling to accurately predict the best kernel parameters without executing the full combinatorial sweep. Operationally, engineers must always enable Clock Locking (nvidia-smi -lgc) on the GPU cluster during autotuning to ensure highly reproducible and accurate benchmark measurements.
). Modern, state-of-the-art approaches (like Ansor or specific MLIR tuning passes) utilize Machine Learning reinforcement models or cost modeling to accurately predict the best kernel parameters without executing the full combinatorial sweep. Operationally, engineers must always enable Clock Locking (nvidia-smi -lgc) on the GPU cluster during autotuning to ensure highly reproducible and accurate benchmark measurements.