Attention Block Tiling Strategies
Tiling decomposes the massive attention matrix into smaller blocks that fit precisely within the SM's ultra-fast SRAM.
Source: mortalapps.com- Tiling decomposes the massive
 attention matrix into smaller blocks (
attention matrix into smaller blocks ( ) that fit precisely within the SM's ultra-fast SRAM.
) that fit precisely within the SM's ultra-fast SRAM. - The fundamental enabler of tiling is the "Online Softmax" algorithm, which mathematically reformulates softmax to execute dynamically in blocks.
- Block sizes are dynamically calculated based on sequence length, head dimension, and available hardware SRAM capacity.
- Effective tiling reduces memory accesses from an intractable
 to a highly efficient
to a highly efficient 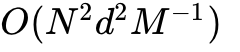 , where
, where  is SRAM size.
is SRAM size.
Why This Matters
Global memory (HBM) is agonizingly slow compared to the compute capacity of Tensor Cores. Without tiling, attention requires transferring the full attention matrix multiple times across this slow bus. By sizing blocks perfectly to the GPU's Shared Memory (SRAM)—which delivers tens of terabytes per second in bandwidth—infrastructure engineers can bypass the notorious "Memory Wall," allowing attention to scale linearly in memory complexity and unlocking large context windows.
Core Intuition
Imagine trying to calculate the average height of a stadium of 100,000 people, but your notebook can only hold 100 names at a time. Instead of pulling all 100,000 names, computing an intermediate number, walking out of the stadium to write it on a giant whiteboard, and repeating, you keep a running tally (a local maximum and a denominator) in your small notebook and update it block by block. Tiling does exactly this for GPUs. It slices the Q, K, and V matrices into chunks that fit the SRAM "notebook," performing local attention and mathematically adjusting it into global attention on the fly.
Technical Deep Dive
The core mechanism involves setting row block size  and column block size
and column block size  such that the required tiles from
such that the required tiles from  , and the intermediate output
, and the intermediate output  fit strictly into the available SRAM size . The formulas derive to
fit strictly into the available SRAM size . The formulas derive to  and
and 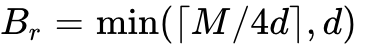 . The mathematical breakthrough enabling this is Online Softmax. Standard softmax requires two complete passes over the data to find the global maximum
. The mathematical breakthrough enabling this is Online Softmax. Standard softmax requires two complete passes over the data to find the global maximum  and the sum of exponentials
and the sum of exponentials  . Online Softmax computes these variables dynamically block by block 4:
. Online Softmax computes these variables dynamically block by block 4: 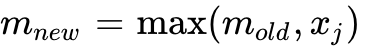 and
and  . By applying the scaling factor
. By applying the scaling factor 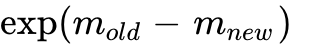 to the previously accumulated denominator and the previous output block, the algorithm correctly patches the local softmax into a globally accurate softmax without ever materializing the full row.
to the previously accumulated denominator and the previous output block, the algorithm correctly patches the local softmax into a globally accurate softmax without ever materializing the full row.
Key Takeaways
Internals / Execution Flow
The kernel begins by allocating global HBM tensors for the final Output , the running maximum , and the running sum . It divides Q into  blocks of size
blocks of size  , and K/V into
, and K/V into  blocks of size
blocks of size  . Iterating in nested loops, the kernel loads corresponding opposite blocks into SRAM. It computes local attention
. Iterating in nested loops, the kernel loads corresponding opposite blocks into SRAM. It computes local attention 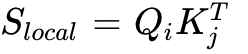 , then immediately updates
, then immediately updates  and
and  using the online scaling math. The output is updated as
using the online scaling math. The output is updated as 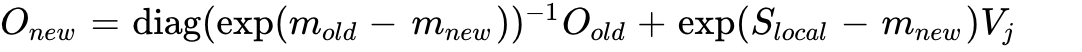 . The accumulator writes back to SRAM, eventually flushing the final globally accurate
. The accumulator writes back to SRAM, eventually flushing the final globally accurate  to HBM only once.
to HBM only once.
Performance Implications
Tiling minimizes HBM accesses dramatically. The theoretical lower bound for exact attention memory passes is bounded by the SRAM size . By maximizing and to fill the 228 KB (H100) or 164 KB (A100) SRAM entirely, the algorithm approaches the theoretical minimum of HBM accesses, yielding up to 4x real-world speedups over un-tiled standard attention. Latency drops proportionately as HBM read/write cycles are eradicated from the critical path.
Common Bottlenecks
Large head dimensions ( ) present a severe bottleneck for tiling. As increases (e.g., to
) present a severe bottleneck for tiling. As increases (e.g., to  ), the block sizes and must shrink to physically fit within SRAM. Smaller block sizes mean more passes over the outer loop are required, increasing memory traffic and aggressively dropping performance. Furthermore, sub-optimal sizing arrays can lead to SRAM fragmentation, yielding padded memory that underutilizes the constrained workspace capacity.
), the block sizes and must shrink to physically fit within SRAM. Smaller block sizes mean more passes over the outer loop are required, increasing memory traffic and aggressively dropping performance. Furthermore, sub-optimal sizing arrays can lead to SRAM fragmentation, yielding padded memory that underutilizes the constrained workspace capacity.
Optimization Strategies
To push tiling further, architects employ Block Sparse Attention. By analyzing the attention mask (such as a causal mask or document boundary mask), tiling logic can skip entire blocks of computation where the output is mathematically guaranteed to be zero. This acts as an algorithmic speedup compounding the hardware speedup. Furthermore, utilizing Register Double Buffering—moving portions of the accumulator directly into the massive register file (256 KB per SM on H100)—keeps SRAM open for even larger K and V tiles.
Interview Guidance
Deriving the online softmax equations from scratch is a notoriously difficult but critical interview question for core ML infrastructure roles. An engineer must be able to demonstrate exactly how to mathematically combine  and to scale previous accumulators and avoid re-reading global memory. Understanding this equation is the gatekeeper to advanced kernel engineering.
and to scale previous accumulators and avoid re-reading global memory. Understanding this equation is the gatekeeper to advanced kernel engineering.