Asynchronous Data Movement Pipelines
Asynchronous pipelines systematically overlap memory loads from global memory with arithmetic computation on the SM.
Source: mortalapps.com- Asynchronous pipelines systematically overlap memory loads from global memory with arithmetic computation on the SM.
- The core purpose is hiding the massive latency of VRAM access (hundreds of cycles) behind dense, uninterrupted math operations.
- The primary optimization idea is Warp Specialization: assigning distinct warps within a block to act solely as data producers or math consumers.
- The most important engineering insight is that true asynchronous execution requires hardware primitives (like mbarrier and TMA) rather than relying on software-level instruction interleaving.
Why This Matters
Without asynchronous pipelines, an SM sits idle waiting for data to traverse the memory hierarchy. In deep learning kernels—specifically FlashAttention and dense GEMMs—performance is strictly gated by how well the execution pipeline masks memory fetches. Multi-stage asynchronous pipelining pushes hardware utilization near theoretical limits, ensuring the Tensor Cores rarely experience starvation.
Core Intuition
Think of a kitchen assembly line. If a chef goes to the fridge, fetches ingredients, cooks them, and then repeats, the stove sits idle during the fetch phase. In an asynchronous pipeline, a prep cook (the producer) continuously fetches ingredients and places them on a staging table (Shared Memory). The chef (the consumer) constantly cooks. They coordinate seamlessly using a bell (the mbarrier). Neither the prep cook nor the chef ever waits for the other if the pipeline is balanced.
Technical Deep Dive
Asynchronous pipelines rely fundamentally on the mbarrier (managed barrier) object, which natively tracks expected transaction bytes arriving in shared memory. In Hopper architectures, Warp Specialization is the ultimate expression of this paradigm. A thread block is partitioned structurally:
Producer Warps: Execute cp.async.bulk.tensor (TMA) instructions to continuously fetch memory into circular buffers in Shared Memory. They never execute math.
Consumer Warps: Wait on the mbarrier. Once data arrives, they execute Tensor Core math (mma.sync or wgmma). They strictly never load from global memory.
Key Takeaways
Internals / Execution Flow
The runtime lifecycle of an asynchronous pipeline is governed by circular buffering. During initialization, the kernel allocates a circular buffer of  stages in Shared Memory and initializes distinct mbarriers. In the prologue, the producer warp issues asynchronous loads for the first
stages in Shared Memory and initializes distinct mbarriers. In the prologue, the producer warp issues asynchronous loads for the first  stages. During the mainloop (often termed a Ping-Pong loop), the consumer warp waits on mbarrier. Simultaneously, the producer warp issues a load for stage , targeting mbarrier[N-1]. The consumer executes math on stage, signals completion, and the buffer pointers logically rotate. In the epilogue, the producer finishes loading, and the consumers drain the remaining stages and write output.
stages. During the mainloop (often termed a Ping-Pong loop), the consumer warp waits on mbarrier. Simultaneously, the producer warp issues a load for stage , targeting mbarrier[N-1]. The consumer executes math on stage, signals completion, and the buffer pointers logically rotate. In the epilogue, the producer finishes loading, and the consumers drain the remaining stages and write output.
Common Bottlenecks
A poorly tuned pipeline size causes starvation or crashes. If is too small, the memory latency isn't fully hidden, and consumers stall waiting on the barrier. If is too large, the required shared memory allocation exceeds the SM's physical capacity (e.g., 228KB on H100), dropping occupancy to 1 or causing catastrophic out-of-memory kernel launch failures.
Optimization Strategies
Engineers must dynamically calculate the optimal pipeline depth as 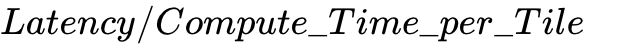 . Adjusting tile sizes helps balance producer and consumer throughput perfectly. Double or triple buffering is mandatory: using at least 3 buffers ensures the producer can write a future tile, while the consumer computes the current tile, and the system drains a past tile. Crucially, Warp Specialization must always be paired with TMA to minimize the producer warp's register usage, preventing spilling.
. Adjusting tile sizes helps balance producer and consumer throughput perfectly. Double or triple buffering is mandatory: using at least 3 buffers ensures the producer can write a future tile, while the consumer computes the current tile, and the system drains a past tile. Crucially, Warp Specialization must always be paired with TMA to minimize the producer warp's register usage, preventing spilling.