Pipeline Parallelism
Slices the neural network longitudinally, distributing different sequential layers across different GPUs (e.g., Layers 1-4 on GPU, Layers 5-8 on GPU 2).
Source: mortalapps.com- Slices the neural network longitudinally, distributing different sequential layers across different GPUs (e.g., Layers 1-4 on GPU, Layers 5-8 on GPU 2).
- Micro-batching algorithms are injected to push concurrent work into the pipeline, preventing massive hardware idle times.
- The fundamental engineering tradeoff revolves around managing the "pipeline bubble"—idle computation time where GPUs stall waiting for upstream or downstream data.
- Essential for scaling models whose sheer depth causes the total parameter count to far exceed the Tensor Parallelism intra-node domain capacity.
Why This Matters
When a model surpasses approximately 50 billion parameters, it can no longer fit efficiently within a single 8-GPU node utilizing solely Tensor Parallelism. To scale execution across the broader datacenter without incurring the catastrophic cross-node latency penalties inherent to TP, Pipeline Parallelism (PP) distributes the model's layers across multiple nodes. Because PP only transmits specific activation tensors between boundary layers over the network (Point-to-Point communication), it remains highly resilient to slower inter-node InfiniBand or Ethernet interconnects.
Core Intuition
The mental model parallels an automotive assembly line. If GPU 1 builds the chassis (Layers 1-10) and GPU 2 installs the engine (Layers 11-20), GPU 2 sits completely idle while GPU 1 processes the first chassis. To mitigate this gross inefficiency, the global training batch is split into smaller "micro-batches." GPU 1 processes micro-batch 1 and passes it to GPU 2. While GPU 2 processes micro-batch, GPU 1 immediately begins processing micro-batch 2. However, at the absolute start (ramp-up phase) and end (ramp-down phase) of the global batch, some GPUs inevitably lack work. This unpreventable idle time constitutes the "pipeline bubble."
Technical Deep Dive
The magnitude of the pipeline bubble in standard 1F1B (One-Forward-One-Backward) scheduling is mathematically defined by the equation 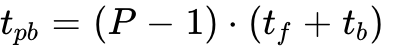 , where
, where  represents the number of pipeline stages, and
represents the number of pipeline stages, and  represent the forward and backward execution times.
represent the forward and backward execution times.
| Scheduling Algorithm | Bubble Size | Memory Footprint |
|---|---|---|
| Communication Volume | GPipe | High |
| Massive (All micro-batches) | Base Point-to-Point | 1F1B |
| High | Moderate (Bounded by ) | Base Point-to-Point |
| Interleaved 1F1B | Medium ( ) ) | Moderate |
High ( Base) Base) | Zero Bubble (ZB-H1) | Near Zero |
| Controllable | Base Point-to-Point 16 | To mathematically reduce the bubble without altering the micro-batch count, Interleaved 1F1B (Virtual Pipeline Parallelism) assigns multiple disjoint, non-contiguous chunks of layers to the same physical GPU. If  represents the number of virtual chunks, the bubble size reduces proportionally to represents the number of virtual chunks, the bubble size reduces proportionally to  , sacrificing increased point-to-point communication volume across the fabric for higher SM utilization. , sacrificing increased point-to-point communication volume across the fabric for higher SM utilization. |
Key Takeaways
Performance Implications
Compute efficiency in PP is heavily dictated by the ratio of micro-batches ( ) to pipeline stages (). Maintaining
) to pipeline stages (). Maintaining  aggressively reduces the bubble fraction but radically increases activation memory constraints. The communication overhead remains relatively low, as only activation tensors of dimension
aggressively reduces the bubble fraction but radically increases activation memory constraints. The communication overhead remains relatively low, as only activation tensors of dimension 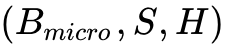 are transmitted via P2P (send/recv) across nodes. However, activation memory per GPU is severe, as the earliest stages in the pipeline must store the activations for micro-batches until their corresponding backward passes traverse back up the network. The implementation of Zero-Bubble (ZB-H1) schedules outperforms standard 1F1B throughput by up to 31% by leveraging the W-pass scheduling heuristic.
are transmitted via P2P (send/recv) across nodes. However, activation memory per GPU is severe, as the earliest stages in the pipeline must store the activations for micro-batches until their corresponding backward passes traverse back up the network. The implementation of Zero-Bubble (ZB-H1) schedules outperforms standard 1F1B throughput by up to 31% by leveraging the W-pass scheduling heuristic.
Real-World Usage
Pipeline parallelism constitutes a staple configuration within Megatron-LM and DeepSpeed. For 100B+ models, standard multi-dimensional topologies utilize  or
or  stretched across different physical nodes. The ZB-PP scheduling algorithms have recently been aggressively adapted into custom Megatron forks by frontier labs to push the theoretical Pareto frontier of memory and throughput.
stretched across different physical nodes. The ZB-PP scheduling algorithms have recently been aggressively adapted into custom Megatron forks by frontier labs to push the theoretical Pareto frontier of memory and throughput.
Common Bottlenecks
Pipeline bubbles dictate the baseline MFU loss. Furthermore, load imbalance severely degrades PP; if computational layers are not uniformly distributed (e.g., placing the computationally heavy embedding layer and the cross-entropy loss calculation on the same physical stage without structural compensation), that specific stage becomes a critical straggler, dictating the latency of the entire pipeline. Activation memory pressure frequently forces engineers to rely on aggressive checkpointing to survive the multiplier.
Interview Guidance
A classic system architecture interview question asks the candidate to calculate the pipeline bubble fraction given stages and micro-batches. (The derived answer is  ). Differentiating operationally between 1F1B and GPipe (which blindly executes all Forward passes before executing all Backward passes, destroying memory) is a strict requirement for senior infrastructure roles.
). Differentiating operationally between 1F1B and GPipe (which blindly executes all Forward passes before executing all Backward passes, destroying memory) is a strict requirement for senior infrastructure roles.