Dynamic Scaling Factors
Dynamic scaling factors adapt the representable window of narrow-precision formats (like FP8) to the continuously shifting distribution of a neural
Source: mortalapps.com- Dynamic scaling factors adapt the representable window of narrow-precision formats (like FP8) to the continuously shifting distribution of a neural network's internal values.
- The core purpose is to map a tensor's physical distribution into the format's safe representable range, preventing catastrophic overflow and underflow during execution.
- The primary optimization strategy is Delayed Scaling, which utilizes the historical statistical maximums from the previous iteration to scale the current iteration.
- The critical engineering insight is that computing the current maximum of a tensor inherently forces a global synchronization block on the GPU; delayed scaling amortizes this completely, eliminating pipeline stalls.
Why This Matters
Training LLMs in standard FP16 is computationally heavy but numerically forgiving. In FP8, particularly the E4M3 format, the maximum representable value is a mere 448.3 Deep neural network gradients and activations frequently experience sudden magnitude spikes spanning millions of values. Without a dynamic scaling factor to divide these tensors and map them proportionally down into the  range, the values instantly overflow to Inf or underflow to, resulting in an immediate NaN loss curve. Making these scales adapt in real-time is the only mechanism that makes FP8 training viable in production.
range, the values instantly overflow to Inf or underflow to, resulting in an immediate NaN loss curve. Making these scales adapt in real-time is the only mechanism that makes FP8 training viable in production.
Core Intuition
Consider quantization as attempting to fit a rapidly expanding and contracting balloon (the tensor's values) into a rigid, tiny box (the FP8 representable range). If you divide the balloon's size by its exact current diameter, it fits perfectly (Current Scaling). However, measuring the balloon right before placing it in the box requires pausing the entire assembly line. If, instead, you assume the balloon's size today is roughly the same as its maximum size over the past few days, you can prep the box in advance. This is Delayed Scaling: using historical statistics to configure the scaling factor for the present, allowing the assembly line (the GPU compute pipeline) to run continuously without pausing for measurements.
Technical Deep Dive
Frameworks like NVIDIA Transformer Engine (TE) execute dynamic scaling using a precise mathematical formula:

The amax represents the maximum absolute value of the tensor. In the Delayed Scaling recipe, the algorithm maintains a rolling buffer of length  (e.g., amax_history_len=16 or 1024) containing past amax values. TE provides specific reduction algorithms to determine the effective amax from this history, commonly utilizing a max function (the highest value seen in the window) to provide a conservative, safe scale that prevents accidental clipping from sudden micro-spikes. Additionally, a safety margin can be applied, mathematically targeting
(e.g., amax_history_len=16 or 1024) containing past amax values. TE provides specific reduction algorithms to determine the effective amax from this history, commonly utilizing a max function (the highest value seen in the window) to provide a conservative, safe scale that prevents accidental clipping from sudden micro-spikes. Additionally, a safety margin can be applied, mathematically targeting 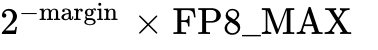 to absorb unforeseen inter-batch distribution shifts.
to absorb unforeseen inter-batch distribution shifts.
Key Takeaways
Internals / Execution Flow
The C/C++ API nvte_delayed_scaling_recipe_amax_and_scale_update manages this concurrent execution 25:
Compute Execution (Single Read): During the forward or backward pass, the GPU reads the tensor from memory exactly once, applies the pre-computed scaling_factor, casts the values to FP8, and immediately dispatches them to the Tensor Cores.
Concurrent Amax Extraction: Simultaneously, the hardware records the actual maximum absolute value of the tensor during this iteration.
History Rotation: The amax_history array is circularly shifted by  , and the newly observed amax replaces the oldest entry.
, and the newly observed amax replaces the oldest entry.
Scale Update: The next iteration's scaling_factor is generated from the updated history buffer, ready for the next compute step.