Grouped-Query Attention (GQA)
Grouped-Query Attention (GQA) dramatically reduces Key-Value (KV) cache memory footprints by sharing a single set of Key/Value heads across multiple Query
Source: mortalapps.com- Grouped-Query Attention (GQA) dramatically reduces Key-Value (KV) cache memory footprints by sharing a single set of Key/Value heads across multiple Query heads.
- It interpolates between Multi-Head Attention (MHA) and Multi-Query Attention (MQA), striking a precise balance between memory efficiency and reasoning quality.
- For a model with
 query heads and
query heads and  KV heads, GQA achieves an
KV heads, GQA achieves an  reduction factor in the KV cache size.
reduction factor in the KV cache size. - Frontier models like Llama 3 rely heavily on GQA, utilizing 8 KV heads for 64 query heads to manage extreme context lengths effectively.
Why This Matters
As context windows scale from 8K to 128K tokens and beyond, KV cache size rapidly overshadows model weights. A single Llama 3 70B request at a 128K context length consumes approximately 42 GB of GPU memory for the KV cache alone. Without GQA, standard MHA would demand over 300 GB for the same request, making concurrent multi-user serving physically impossible on a standard 8-GPU node. GQA is the architectural backbone that enables the economic feasibility of long-context LLMs in production environments.
Core Intuition
In MHA, every query head gets its own dedicated key and value head. This is akin to assigning a dedicated librarian (KV) to every single student (Q) in a library. In MQA, all students share exactly one librarian, which is incredibly fast but creates bottlenecks in complex lookups, leading to quality degradation. GQA groups students into cohorts and assigns one librarian per cohort. By sharing 1 KV head across 8 Q heads, the memory footprint drops by 87.5% while retaining enough multidimensional representational capacity to maintain high reasoning performance.
Technical Deep Dive
The KV Cache size for GQA can be calculated deterministically and scales linearly with sequence length:
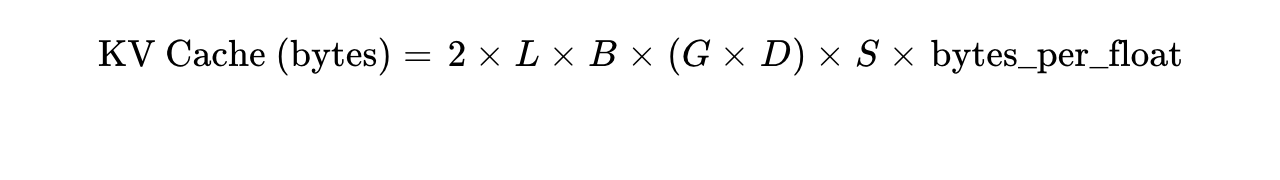
Where  is the number of layers,
is the number of layers,  is batch size, is the number of KV groups (heads),
is batch size, is the number of KV groups (heads),  is head dimension, and
is head dimension, and  is sequence length. If Llama 3 70B operates with 64 query heads and 8 KV heads (
is sequence length. If Llama 3 70B operates with 64 query heads and 8 KV heads ( ), it requires exactly 8 times less memory than an MHA equivalent where
), it requires exactly 8 times less memory than an MHA equivalent where  . The execution semantics broadcast the KV heads across the Q heads dynamically during the attention matrix multiplication, mapping a shape of (B, 8, S, D) to (B, 64, S, D) implicitly within the CUDA kernel without ever materializing the duplicated tensors in global memory.
. The execution semantics broadcast the KV heads across the Q heads dynamically during the attention matrix multiplication, mapping a shape of (B, 8, S, D) to (B, 64, S, D) implicitly within the CUDA kernel without ever materializing the duplicated tensors in global memory.
Key Takeaways
compared to standard MHA.Internals / Execution Flow
During the forward pass, input token embeddings are passed through linear projections to generate 64 Q heads, 8 K heads, and 8 V heads. The 8 K and V heads are immediately written to the PagedAttention memory blocks to update the KV cache. During the attention calculation, the compute kernel loads the K and V heads from SRAM and conceptually broadcasts them 8 times. The matmul executes such that  attend to
attend to  ,
,  attend to
attend to  , and so forth. Finally, the outputs of all 64 query heads are concatenated and passed through the dense output projection matrix to form the final contextualized token representation.
, and so forth. Finally, the outputs of all 64 query heads are concatenated and passed through the dense output projection matrix to form the final contextualized token representation.
Performance Implications
GQA directly shifts the boundary of the Memory Wall. By shrinking the KV cache by an order of magnitude, system operators can massively increase batch sizes () or support dramatically longer context lengths () within the same VRAM budget. A 32K context with 8 concurrent users under Llama 3.1 70B requires approximately 86 GB of KV cache; this would balloon to roughly 688 GB under MHA, which would fundamentally alter the required cluster size and deployment cost.
Optimization Strategies
Engineers often apply KV Cache Quantization on top of GQA. Storing the KV heads in FP8 or INT8 formats compounds the memory savings, yielding an additional 50% or 75% reduction with minimal degradation to accuracy. Additionally, models initially trained as MHA can be mathematically collapsed into GQA models via mean-pooling the KV heads, followed by a brief fine-tuning phase (known as uptraining) to restore performance, saving massive pre-training costs while unlocking faster inference.
Interview Guidance
Interviewers frequently ask candidates to calculate the exact VRAM footprint of a model in a production scenario. Knowing the GQA formula and understanding that replaces in the KV cache equation is a critical pass/fail requirement. Candidates who fail to ask "Is this model MHA or GQA?" before calculating memory sizes are heavily penalized in system design rounds.