3D Parallelism Topologies
Mathematically combines Data Parallelism (DP), Tensor Parallelism (TP), and Pipeline Parallelism (PP) to successfully train massive foundation models.
Source: mortalapps.com- Mathematically combines Data Parallelism (DP), Tensor Parallelism (TP), and Pipeline Parallelism (PP) to successfully train massive foundation models.
- Explicitly maps specific parallel strategies to matching physical hardware interconnects (e.g., executing TP strictly on NVLink, and PP/DP across InfiniBand).
- Ensures that total parameter size, dynamic activation memory, and communication overhead simultaneously fit within the cluster's hard constraints.
- Forms the core architectural blueprint governing frameworks like Megatron-LM and DeepSpeed.
Why This Matters
No single parallelism strategy is computationally sufficient for training a 100B+ parameter model. DP/FSDP violently hits network bandwidth limits; TP hits extreme latency limits and mathematically cannot cross nodes; PP suffers from unacceptable pipeline bubbles. By mathematically multiplying these orthogonal strategies ( ), engineers can construct unified 3D parallelism topologies that explicitly exploit the strengths of each method while mitigating their compounding weaknesses, allowing execution to operate efficiently across thousands of GPUs.
), engineers can construct unified 3D parallelism topologies that explicitly exploit the strengths of each method while mitigating their compounding weaknesses, allowing execution to operate efficiently across thousands of GPUs.
Core Intuition
The intuition requires visualizing a datacenter as a series of nested, hierarchical networks. Inside a physical server, 8 GPUs are intimately connected by ultra-fast NVLink providing ~900 GB/s of bandwidth. Between servers, nodes are connected by a slower InfiniBand fabric providing ~50 GB/s.
The infrastructure engineer must place the most communication-heavy strategy (TP, with its multiple blocking AllReduce operations) exclusively inside the fast NVLink domain. PP (which only passes small activation boundaries) is placed across the slower InfiniBand network. Finally, to scale the global batch size, this entire TP/PP cluster is wrapped in Data Parallelism (or ZeRO), forming a cohesive 3D computational grid.
Technical Deep Dive
Let  represent the total number of GPUs in the cluster.
represent the total number of GPUs in the cluster. 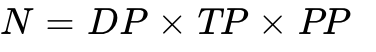 .
.
| Topology Dimension | Scope |
|---|---|
| Bandwidth Requirement | Sharding Target |
| Tensor (TP) | Intra-node |
| Extreme (NVLink) | Intra-layer weights / activations |
| Pipeline (PP) | Inter-node |
| Low (P2P Send/Recv) | Inter-layer stages |
| Data (DP) | Global |
| High (AllReduce/ReduceScatter) | Gradients / Optimizer State |
| TP Dimension: Typically $TP \in $. It requires instantaneous synchronization. | PP Dimension: Typically $PP \in $. It has minimal bandwidth requirements, but demands careful micro-batching ( ) configuration to reduce the ) configuration to reduce the  pipeline bubble. pipeline bubble. |
DP Dimension:  . It synchronizes gradients globally at the end of the step. If Sequence Parallelism (SP) is introduced, it is typically tightly coupled with TP (
. It synchronizes gradients globally at the end of the step. If Sequence Parallelism (SP) is introduced, it is typically tightly coupled with TP ( ) to form a 4D grid, or mapped independently if utilizing DeepSpeed Ulysses. If MoEs are utilized, Expert Parallelism (EP) partially replaces or heavily augments the DP/TP domains.
) to form a 4D grid, or mapped independently if utilizing DeepSpeed Ulysses. If MoEs are utilized, Expert Parallelism (EP) partially replaces or heavily augments the DP/TP domains.
Key Takeaways
Performance Implications
Compute efficiency is excellent, provided the chosen micro-batch sizes are sufficiently large enough to mathematically mask the inherent PP bubbles. Communication overhead is meticulously optimized to physical hardware limits, allowing the NVLink domain to completely absorb the brutal TP traffic, while the broader IB fabric handles the more tolerant DP/PP traffic. Memory per GPU is highly optimized, as massive model states are fractionalized by 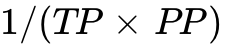 (and fractured further by ZeRO shards).
(and fractured further by ZeRO shards).
Common Bottlenecks
Navigating the Configuration Search Space is notoriously difficult; finding the mathematically optimal 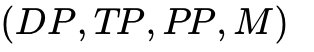 tuple for a specific model size on a specific cluster is an NP-hard problem. A poor configuration leads to catastrophic MFU degradation. Furthermore, Stragglers in 3D Space are devastating: a single hardware failure in one PP rank instantly halts the entire 3D mesh. Memory Imbalance also plagues operations, as PP stages placed at the network edges (handling the massive embedding tables and output projections) often consume significantly more memory, requiring manual offset tuning.
tuple for a specific model size on a specific cluster is an NP-hard problem. A poor configuration leads to catastrophic MFU degradation. Furthermore, Stragglers in 3D Space are devastating: a single hardware failure in one PP rank instantly halts the entire 3D mesh. Memory Imbalance also plagues operations, as PP stages placed at the network edges (handling the massive embedding tables and output projections) often consume significantly more memory, requiring manual offset tuning.
Interview Guidance
A guaranteed interview question for infrastructure roles: "You have 1024 GPUs (configured as 128 nodes of 8 GPUs). Exactly how do you parallelize a 175B parameter model?" The expected answer must explicitly define  strictly inside the node,
strictly inside the node,  strung across the nodes, and
strung across the nodes, and  . The candidate must explicitly explain why a configuration of
. The candidate must explicitly explain why a configuration of  is a fatal error due to the absence of cross-node NVLink.
is a fatal error due to the absence of cross-node NVLink.