Multi-Query Attention (MQA)
Multi-Query Attention (MQA) represents the extreme variant of Grouped-Query Attention where all query heads share exactly one single Key and Value head .
Source: mortalapps.com- Multi-Query Attention (MQA) represents the extreme variant of Grouped-Query Attention where all
 query heads share exactly one single Key and Value head (
query heads share exactly one single Key and Value head ( ).
). - It delivers the absolute maximum architectural reduction in KV cache memory footprint, providing a compression factor equal to the number of query heads .
- While maximizing inference throughput and minimizing VRAM, MQA often suffers from observable capacity degradation in complex, long-context reasoning tasks.
- It remains heavily utilized in highly optimized code models and architectures designed for deployment on edge devices with strict memory limits.
Why This Matters
For specialized models deployed on consumer hardware (such as 24 GB VRAM GPUs) or mobile devices, memory constraints are absolute and unforgiving. MQA reduces the KV cache footprint so aggressively that context lengths can be extended tremendously without triggering OOM errors. It represents the extreme end of the memory-vs-quality Pareto frontier, allowing system architects to serve massive context windows on hardware that would otherwise be completely incapable of booting the model.
Core Intuition
If MHA assigns one librarian to every student, and GQA assigns one librarian to a study group, MQA assigns a single librarian to the entire library. The librarian (representing the K and V tensors) only has one conceptual representation of the facts. Every student (Q) must query this exact same representation. While extremely fast and requiring almost no desk space (VRAM) for the librarian, the nuance of the information retrieved can degrade because the K/V projection lacks multidimensional diversity. The model loses the ability to simultaneously view the context from many distinct angles.
Technical Deep Dive
The KV Cache size for MQA collapses the head dimension variable entirely. The formula simplifies to:
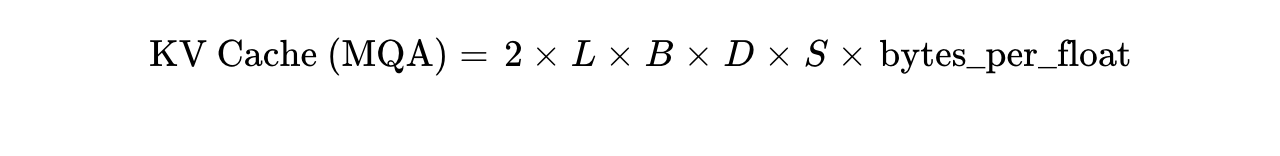
Notice that or  is entirely absent from the formula. For a 32-layer model with a 128-dimensional head and 32 query heads, MQA shrinks the per-token KV footprint from,384 bytes to just 512 bytes. Over a span of,024 tokens, this drops the memory requirement from 512 MB to a mere 16 MB. This
is entirely absent from the formula. For a 32-layer model with a 128-dimensional head and 32 query heads, MQA shrinks the per-token KV footprint from,384 bytes to just 512 bytes. Over a span of,024 tokens, this drops the memory requirement from 512 MB to a mere 16 MB. This  reduction completely eliminates memory bandwidth as the primary bottleneck during decoding, transitioning the workload into a purely compute-bound state.
reduction completely eliminates memory bandwidth as the primary bottleneck during decoding, transitioning the workload into a purely compute-bound state.
Key Takeaways
..Internals / Execution Flow
During the forward pass, the token embeddings are projected into distinct query heads, but only a single key vector and a single value vector are created. These singular K and V vectors are cached in VRAM. During the attention phase, a highly optimized kernel uses stride=0 across the head dimension for the KV matrices. All queries independently compute dot products against the identical K vector in parallel, yielding different attention scores (due to the different Q vectors). These scores are then used to compute weighted sums of the identical V vector.
Optimization Strategies
To compensate for the lack of representational capacity in MQA, architects often increase the individual head dimension  or apply more complex Rotary Position Embeddings (RoPE) to the single KV head. Additionally, through a process called "Up-Cycling," models trained as MQA can be split into GQA during a fine-tuning stage to inject representational capacity back into the architecture for downstream tasks.
or apply more complex Rotary Position Embeddings (RoPE) to the single KV head. Additionally, through a process called "Up-Cycling," models trained as MQA can be split into GQA during a fine-tuning stage to inject representational capacity back into the architecture for downstream tasks.
Interview Guidance
In system design interviews, proposing MQA is often the correct answer to prompts like: "How do we deploy a 15B parameter model with a 64K context window on a single 24GB consumer GPU?" Candidates should be able to derive the KV cache savings factor () instantly and explain the tradeoff between arithmetic intensity and reasoning quality.