MR-GPTQ Runtime Optimization
Micro-Rotated-GPTQ (MR-GPTQ) is an advanced evolution of the GPTQ algorithm tailored to counteract the severe accuracy degradation inherent in ultra-low
Source: mortalapps.com- Micro-Rotated-GPTQ (MR-GPTQ) is an advanced evolution of the GPTQ algorithm tailored to counteract the severe accuracy degradation inherent in ultra-low precision FP4 (4-bit floating point) formats.
- The core purpose is to make formats like NVFP4 and MXFP4 mathematically viable for production deployment without suffering the massive accuracy collapse seen when transitioning from INT4.
- The primary optimization fuses block-wise Hadamard rotations with a format-specific scale search directly into the GPTQ pipeline.
- The essential engineering insight is that standard global rotational invariance fails under FP4 due to micro-scale saturation; MR-GPTQ instead injects localized micro-rotations to flatten variance exactly within the hardware's strict block dimensions.
Why This Matters
While the Blackwell architecture natively supports MXFP4 and NVFP4, empirical research revealed a harsh reality: FP4 is not an automatic upgrade over INT4. Native Post-Training Quantization (PTQ) directly into FP4 suffers catastrophic accuracy drops on massive language models because the non-linear bin spacing of floating-point formats violently amplifies outliers. MR-GPTQ bridges this critical gap, recovering up to 96.1% of the original FP16 accuracy. It makes the promise of ultra-low precision FP4 hardware acceleration a practical reality for production.
Core Intuition
Hadamard rotations are mathematical transformations that smear extreme outliers, effectively flattening the distribution of a tensor to make it easier to quantize. However, applying a massive global rotation to an entire matrix ignores the architecture of FP4 formats, which calculate their scaling factors locally in tiny micro-blocks of 16 or 32 elements. If variance isn't smoothed within those tiny blocks, the scales still saturate. MR-GPTQ aligns the mathematical rotation matrix perfectly with the hardware's micro-scaling block dimensions, ensuring that the local variance within every single micro-block is flattened, yielding an optimal, tight FP4 scale.
Technical Deep Dive
For a linear layer containing quantized weights  and activations
and activations  , MR-GPTQ introduces block-wise Hadamard rotations
, MR-GPTQ introduces block-wise Hadamard rotations  . These consist of
. These consist of  diagonal blocks where
diagonal blocks where  is a power-of-two strictly aligned with the hardware's block size. Mathematically, the operation manifests as:
is a power-of-two strictly aligned with the hardware's block size. Mathematically, the operation manifests as:
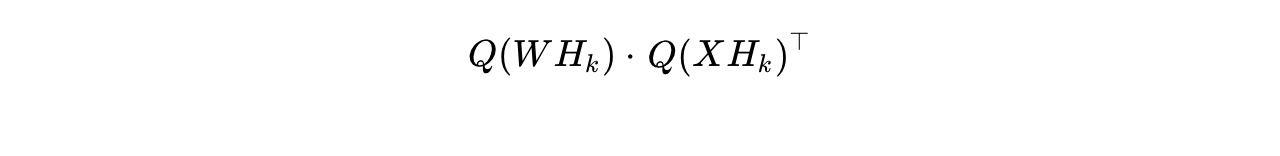
where  is the highly-constrained quantization function. MR-GPTQ employs format-specialized strategies to navigate different hardware limits:
is the highly-constrained quantization function. MR-GPTQ employs format-specialized strategies to navigate different hardware limits:
MXFP4 (Block size, E8M0 scale): Due to the wider block size and restrictive integer-only scale, this format requires aggressive micro-rotation to mitigate local variance.
NVFP4 (Block size, E4M3 scale): Given its tighter block size and floating-point scale, MR-GPTQ utilizes a highly targeted scale search optimization deep within the GPTQ error compensation loop, fine-tuning the bins to minimize error.
Key Takeaways
) precisely matched to hardware block limits.Internals / Execution Flow
The MR-GPTQ execution pipeline blends offline transformation with dynamic runtime execution:
Pre-rotation: During offline compilation, the weights and the activation calibration data are multiplied by the structured block-wise Hadamard matrix .
Format-Aware GPTQ: The standard GPTQ algorithm iterates through the matrix. However, when selecting the optimal quantization grid, it explicitly models the non-linear constraints of the E2M1 structure and the specific micro-block scale (E4M3 or E8M0).
Second-Order Updates: Compensation vectors are calculated and applied exclusively to the remaining rotated weights.
Kernel Epilogue Integration: At runtime, the inverse micro-rotation must be executed dynamically. This is integrated into the GPU kernel registers (utilizing the optimized QuTLASS library) immediately prior to the GEMM execution, preventing any memory bandwidth penalty.