Standard Multi-Head Attention Bottlenecks
Standard multi-head attention (MHA) exhibits quadratic scaling with sequence length, leading to catastrophic memory and latency overheads for long
Source: mortalapps.com- Standard multi-head attention (MHA) exhibits quadratic scaling
 with sequence length, leading to catastrophic memory and latency overheads for long contexts.
with sequence length, leading to catastrophic memory and latency overheads for long contexts. - The core bottleneck is the explicit materialization of the
 attention matrix in the GPU's High Bandwidth Memory (HBM).
attention matrix in the GPU's High Bandwidth Memory (HBM). - HBM bandwidth significantly restricts execution speed, creating a memory-bound regime where the GPU's arithmetic units sit idle.
- Exact attention computation requires global statistics (maximum and sum of exponentials), traditionally forcing multiple sequential memory passes over the data.
Why This Matters
Standard MHA architectures govern the theoretical and practical boundaries of large language model capabilities. Materializing an intermediate matrix in HBM becomes an intractable physics problem for contexts beyond a few thousand tokens. On modern accelerators like the NVIDIA A100 or H100, which boast massive theoretical floating-point operation (FLOP) counts but relatively limited HBM capacity and bandwidth, computing exact attention iteratively without optimization results in severe utilization drop-offs. Understanding these hardware-level constraints is critical for infrastructure engineers, as scaling model context lengths is economically impossible without fundamentally rewriting the attention memory access patterns.
Core Intuition
Attention is mathematically a weighted sum of values, where the weights are determined by the similarity between queries and keys. In a standard setup, computing this involves matrix multiplication, normalization via softmax, and another matrix multiplication. The standard execution paradigm acts as a highly inefficient "memory round-trip" machine. A tensor is computed, written out to the main GPU memory (HBM), read back into the on-chip static RAM (SRAM) for the next operation (such as softmax), written back to HBM, and read yet again. Because mathematical operations outpace data movement on modern silicon by orders of magnitude, the system starves the arithmetic logic units (ALUs) while waiting on the memory bus. The architecture is starved not for compute, but for data feed rates.
Technical Deep Dive
For a sequence length  and head dimension
and head dimension  , the inputs are
, the inputs are 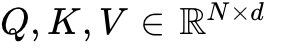 . The attention mechanism sequentially computes the unnormalized scores, the normalized probabilities, and the final output. The standard PyTorch or CUDA implementation allocates distinct memory spaces for the score matrix and the probability matrix. For a sequence length of 128,000 tokens, a single head's
. The attention mechanism sequentially computes the unnormalized scores, the normalized probabilities, and the final output. The standard PyTorch or CUDA implementation allocates distinct memory spaces for the score matrix and the probability matrix. For a sequence length of 128,000 tokens, a single head's  matrix at BF16 precision consumes roughly 32 GB of VRAM. When multiplied by multiple attention heads, this requirement instantly exceeds the 80 GB capacity of an A100 or H100 SXM5 GPU. Furthermore, the time complexity means that doubling the context window quadruples the required arithmetic operations and memory footprints, triggering out-of-memory (OOM) failures natively before computation even completes.
matrix at BF16 precision consumes roughly 32 GB of VRAM. When multiplied by multiple attention heads, this requirement instantly exceeds the 80 GB capacity of an A100 or H100 SXM5 GPU. Furthermore, the time complexity means that doubling the context window quadruples the required arithmetic operations and memory footprints, triggering out-of-memory (OOM) failures natively before computation even completes.
Key Takeaways
memory footprint.Internals / Execution Flow
The standard MHA runtime lifecycle follows a strict sequence of memory loads and stores across the GPU memory hierarchy. The GPU first reads  and
and  from HBM into the Streaming Multiprocessor (SM) SRAM to execute the matrix multiplication
from HBM into the Streaming Multiprocessor (SM) SRAM to execute the matrix multiplication 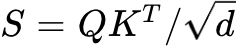 . The resulting matrix
. The resulting matrix  is written back to HBM. Subsequently, the GPU must load back from HBM into SRAM to perform the softmax operation, which itself traditionally requires multiple passes to find the row-wise maximum and sum of exponentials. The normalized probability matrix
is written back to HBM. Subsequently, the GPU must load back from HBM into SRAM to perform the softmax operation, which itself traditionally requires multiple passes to find the row-wise maximum and sum of exponentials. The normalized probability matrix  is written to HBM, only to be read back alongside
is written to HBM, only to be read back alongside  to compute the final output projection
to compute the final output projection  , which is written to HBM one final time.
, which is written to HBM one final time.
Performance Implications
This multi-pass sequence translates to 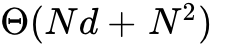 HBM accesses. Because the HBM bandwidth on an A100 is around 1.6 to 2.0 TB/s, while the L1 cache and Shared Memory bandwidth is phenomenally higher (approximately 19 TB/s aggregate), the execution is intensely memory-bound. The Tensor Cores remain idle while data traverses the HBM-L2-L1 hierarchy, limiting overall Model FLOPs Utilization (MFU) to typically below 20-30%. The latency of a standard attention pass is therefore dictated entirely by memory bandwidth limits rather than the GPU's theoretical compute capacity.
HBM accesses. Because the HBM bandwidth on an A100 is around 1.6 to 2.0 TB/s, while the L1 cache and Shared Memory bandwidth is phenomenally higher (approximately 19 TB/s aggregate), the execution is intensely memory-bound. The Tensor Cores remain idle while data traverses the HBM-L2-L1 hierarchy, limiting overall Model FLOPs Utilization (MFU) to typically below 20-30%. The latency of a standard attention pass is therefore dictated entirely by memory bandwidth limits rather than the GPU's theoretical compute capacity.
Optimization Strategies
The primary architectural strategy to resolve this bottleneck is kernel fusion combined with hardware-aware tiling. By mathematically fusing the query-key multiplication, the softmax normalization, and the value multiplication into a single customized GPU kernel, the intermediate matrix never leaves the SM's SRAM. This optimization shifts the bottleneck from the slow HBM bus back to the highly capable Tensor Cores, dramatically improving throughput and completely circumventing the memory allocation problem.