FlashAttention-3 Asynchronous Execution
FlashAttention-3 is designed explicitly for the Hopper (H100/H800) architecture, leveraging advanced asynchronous execution primitives.
Source: mortalapps.com- FlashAttention-3 is designed explicitly for the Hopper (H100/H800) architecture, leveraging advanced asynchronous execution primitives.
- It introduces warp-specialized software pipelining, strictly dividing warps into pure "producers" (data movement via TMA) and "consumers" (computation via WGMMA).
- It utilizes 2-stage pipelining to hide the low-throughput softmax operations entirely in the shadow of asynchronous matrix multiplications.
- It introduces incoherent processing to support highly accurate FP8 operations, approaching 1.2 PFLOPs/s on Hopper silicon.
Why This Matters
While FlashAttention-2 excels on the Ampere (A100) architecture, it achieves only roughly 35% utilization on Hopper (H100) GPUs because it strictly enforces a synchronous model of data movement and computation. Hopper GPUs feature a massive 228 KB of shared memory per SM alongside novel asynchronous hardware instructions. Without utilizing the Tensor Memory Accelerator (TMA) and Warpgroup Matrix Multiply-Accumulate (WGMMA) instructions, standard kernels strand the majority of the H100's immense computational potential, wasting millions of dollars in capital expenditure on high-end clusters.
Core Intuition
Think of previous attention kernels as chefs who fetch ingredients from the refrigerator (HBM), bring them to the counter (SRAM), chop them (Compute), and then walk back to the refrigerator. This process is highly synchronous. FlashAttention-3 creates a specialized kitchen: "Producer" warps only fetch data and run the conveyor belt (TMA), while "Consumer" warps never leave the chopping station (WGMMA). Because the conveyor belt operates asynchronously, the choppers always have ingredients ready. Furthermore, slow non-GEMM operations like softmax are "hidden" by having one group of consumers chop while the other does the slow mixing via pingpong scheduling.
Technical Deep Dive
FlashAttention-3 relies heavily on the Tensor Memory Accelerator (TMA), a specialized hardware unit that offloads index calculation and out-of-bounds predication from the ALU. TMA directly transfers memory blocks from HBM to SRAM asynchronously, freeing up registers to expand tile sizes. Concurrently, Hopper's Tensor Cores require WGMMA instructions to reach peak throughput. FlashAttention-3 organizes threads into Warpgroups—4 aligned consecutive warps representing 128 threads—to issue massive matrix multiply instructions directly against SRAM. To support FP8 low-precision without sacrificing accuracy due to outlier activations common in LLMs, FA3 introduces incoherent processing. It applies a Walsh-Hadamard transform with random signs to Q and K. This 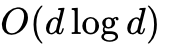 operation spreads outliers out, dropping FP8 numerical error by 2.6x.
operation spreads outliers out, dropping FP8 numerical error by 2.6x.
Key Takeaways
Internals / Execution Flow
The kernel dynamically allocates roles to warps: typically 1 Producer Warpgroup and 2 Consumer Warpgroups. The Producer issues a TMA command to pull K and V into the pipeline buffer. Synchronization relies on wgmma.commit_group and wait_group barriers. Execution follows Pingpong Scheduling (Inter-Warpgroup overlap): Consumer Warpgroup 1 executes WGMMA for the  multiplication while Consumer Warpgroup 2 evaluates the exponential functions for softmax. Within a single warpgroup (Intra-Warpgroup pipelining), the softmax calculation overlaps with active GEMM accumulators via advanced dynamic register allocation, ensuring maximum utilization.
multiplication while Consumer Warpgroup 2 evaluates the exponential functions for softmax. Within a single warpgroup (Intra-Warpgroup pipelining), the softmax calculation overlaps with active GEMM accumulators via advanced dynamic register allocation, ensuring maximum utilization.
Performance Comparisons
| Architecture Feature | NVIDIA A100 (Ampere) | NVIDIA H100 (Hopper) |
|---|---|---|
| Impact on FlashAttention | Max Threads / SM | 2048 |
| 2048 | Determines occupancy ceilings. | SRAM per SM |
| 164 KB | 228 KB | Enables larger block tiling ( ). ). |
| L2 Cache | 40 MB | 50 MB |
| Improves global hit rates during attention. | Matmul Instructions | mma.sync |
| WGMMA (Asynchronous) | Enables warp-specialized FA3 pipelines. | Data Movement |
| Synchronous Load | TMA (Asynchronous) | Offloads ALU address calculation in FA3. |