GPTQ Quantization
GPTQ is an advanced Optimal Brain Quantization (OBQ) algorithm that quantizes weights iteratively while mathematically compensating for the introduced
Source: mortalapps.com- GPTQ is an advanced Optimal Brain Quantization (OBQ) algorithm that quantizes weights iteratively while mathematically compensating for the introduced error by adjusting the remaining unquantized weights.
- The core purpose is to accurately compress massive 100B+ parameter transformer models down to 3-bit or 4-bit precision within a few GPU hours.
- The primary optimization is utilizing the Cholesky decomposition of the inverse Hessian matrix combined with "lazy" block-wise parameter updates.
- The critical engineering insight is that directly computing the inverse Hessian matrix across billions of parameters accumulates catastrophic floating-point errors; Cholesky decomposition provides the deep numerical stability required to make this math viable at scale.
Why This Matters
Prior to the advent of GPTQ, iterative post-training quantization techniques like OBQ exhibited cubic time complexity, taking days or weeks to compress massive models. GPTQ introduced a suite of algebraic and systems-level optimizations that permitted the quantization of trillion-parameter architectures on standard consumer hardware (e.g., an RTX 3090) in a matter of hours. This architectural breakthrough functionally democratized the era of local LLM hosting, proving that immense models could be efficiently packed into single nodes without structural retraining.
Core Intuition
Imagine attempting to fit an oddly shaped collection of rocks (high-precision weights) into a rigid grid of identical boxes (low-bit quantized bins). Every time you force a rock into a box, you shave a little piece off, creating a gap or an error. Instead of simply accepting the error, you take the shaved material and dynamically stick it onto the remaining unquantized rocks to perfectly offset the mistake. GPTQ calculates exactly how to distribute this "shaved material" using the Hessian matrix, which mathematically models precisely how sensitive the final output of the neural network layer is to changes in any specific weight.
Technical Deep Dive
GPTQ addresses the layer-wise compression problem by seeking to minimize the squared error of the output:  . When a specific weight
. When a specific weight  is quantized, the mathematically optimal adjustment
is quantized, the mathematically optimal adjustment  to be applied to all remaining unquantized weights is determined by the inverse Hessian matrix
to be applied to all remaining unquantized weights is determined by the inverse Hessian matrix 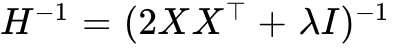 . Directly updating this inverse Hessian using standard row/column removal (Gaussian elimination):
. Directly updating this inverse Hessian using standard row/column removal (Gaussian elimination):
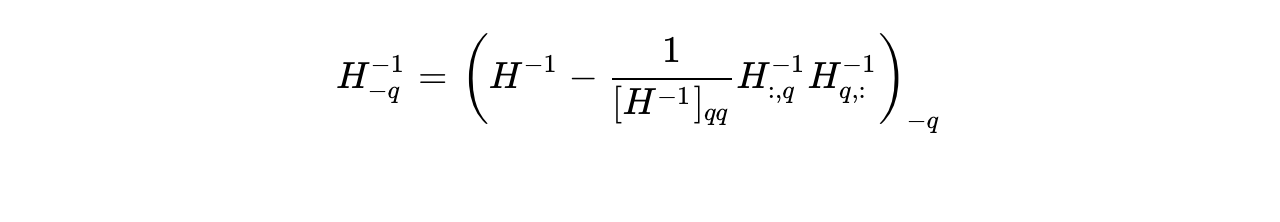
accumulates fatal numerical floating-point errors on massive matrices. To ensure stability, GPTQ precomputes the Cholesky decomposition  . The upper triangular matrix
. The upper triangular matrix  encapsulates all necessary scaling information, entirely avoiding the need for repeated unstable matrix inversions during the compensation loop.
encapsulates all necessary scaling information, entirely avoiding the need for repeated unstable matrix inversions during the compensation loop.
Key Takeaways
 to stabilize massive matrices.
to stabilize massive matrices.Internals / Execution Flow
The GPTQ execution pipeline occurs entirely offline:
Hessian Construction: A calibration dataset is passed through the layer to gather input activations  and compute the foundational Hessian
and compute the foundational Hessian  .
.
Cholesky Decomposition: The algorithm computes the stable decomposition upfront.
Block-wise Loop: Rather than updating weights one by one across the entire matrix, GPTQ groups the columns into blocks (e.g.,  ).
).
Local Updates: For each column within the current block, the weight is quantized, the error is calculated, and the algorithm adjusts only the remaining weights within that local block.
Lazy Global Updates: Once the localized block is completely processed, a highly efficient, vectorized matrix multiplication applies the accumulated block errors to all remaining weights in the larger matrix simultaneously.
Optimization Strategies
To combat numerical instability, particularly on massive layers, a dampening factor (typically 1% of the average diagonal value) is added to the diagonal elements of the Hessian before inversion. Additionally, the algorithm utilizes the ActOrder (Activation Order) heuristic, sorting the weights so that those associated with the highest activation variance are quantized last, preserving the most mathematically volatile data with the highest fidelity.