KV Cache Quantization
KV Cache quantization compresses the dynamic Key and Value tensors stored in High Bandwidth Memory (HBM) during autoregressive decoding down to 8-bit or
Source: mortalapps.com- KV Cache quantization compresses the dynamic Key and Value tensors stored in High Bandwidth Memory (HBM) during autoregressive decoding down to 8-bit or 4-bit precision.
- The core purpose is to radically expand the maximum context window length and concurrent batch size limits by drastically reducing the memory footprint of stored tokens.
- The primary optimization relies on FP8 (E4M3) scaling natively integrated with the FlashAttention 3 backend.
- The critical engineering insight is that during long-context decoding, inter-token latency (ITL) grows linearly with context length because the entire KV cache must be read; halving the cache size directly halves the ITL slope.
Why This Matters
In standard Transformer architectures, generating a new token requires attending to all previously generated tokens. At a batch size of 128 utilizing a 32k context window, a standard BF16 KV cache for a 70B model can consume hundreds of gigabytes of VRAM—often far exceeding the memory footprint of the model weights themselves. Quantizing the cache to FP8 effectively doubles the context length capacity of the system, acting as a critical scalability lever for advanced agentic and RAG (Retrieval-Augmented Generation) workflows.
Core Intuition
The attention mechanism is universally memory-bound during decoding. The GPU compute cores sit idle, waiting for the massive Key and Value tensors to travel from VRAM to the SM. If those tensors are formatted and packed in FP8, the physical memory bus transfers twice as many tokens per clock cycle. The underlying math is absolute: fewer bytes to fetch equals faster generation, which directly translates to a lower Inter-Token Latency (ITL).
Technical Deep Dive
Implementations in state-of-the-art frameworks like vLLM support two primary configurations for FP8 KV cache quantization:
Per-tensor scaling: A single, global scale is applied equally to the entire Q, K, and V tensor arrays.
Per-attention-head scaling: (Requires the FlashAttention backend). Each individual query or KV head maintains its own distinct scale ( ).
).
When scaling is highly dynamic (e.g., computed per-token at runtime), distinct FP32 auxiliary buffers must be allocated in memory to store these scales. This introduces an unexpected memory overhead that must be meticulously accounted for in the PagedAttention memory planner, otherwise, the system will suffer OOM crashes despite the quantization.
Key Takeaways
Internals / Execution Flow
The runtime lifecycle of the quantized cache is as follows:
Prefill Ingestion: Incoming prompt tokens are processed. Keys and Values are computed in high-precision, mathematically scaled, cast to FP8, and written securely to the PagedAttention KV blocks in memory.
Query Quantization: Queries are quantized just-in-time utilizing a fused torch.compile implementation to avoid heavy per-token Python dispatch overhead.
Decode Attention: The FlashAttention 3 kernel fetches the FP8 keys, values, and queries concurrently.
Hardware Execution: The massive dot products occur inside the FP8 Tensor Cores. FlashAttention tile sizes (e.g., 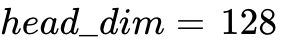 ) are heavily tuned at the hardware level to prevent register spills resulting from the two-level FP32 internal accumulation.
) are heavily tuned at the hardware level to prevent register spills resulting from the two-level FP32 internal accumulation.
Performance Implications
For a Llama-3.1-8B model running on a B200 GPU, activating the FP8 KV Cache reduces the decode ITL slope to approximately 54% of the BF16 baseline (dropping from  to
to  ms/token). Because of the fixed algorithmic overhead required for format conversion, FP8 mathematically breaks even with BF16 speeds at roughly a,000-token context length. For sliding-window attention layers, the benefits diminish entirely because the cache size is strictly capped; therefore, production systems often strategically skip quantizing sliding-window layers entirely to preserve precision.
ms/token). Because of the fixed algorithmic overhead required for format conversion, FP8 mathematically breaks even with BF16 speeds at roughly a,000-token context length. For sliding-window attention layers, the benefits diminish entirely because the cache size is strictly capped; therefore, production systems often strategically skip quantizing sliding-window layers entirely to preserve precision.